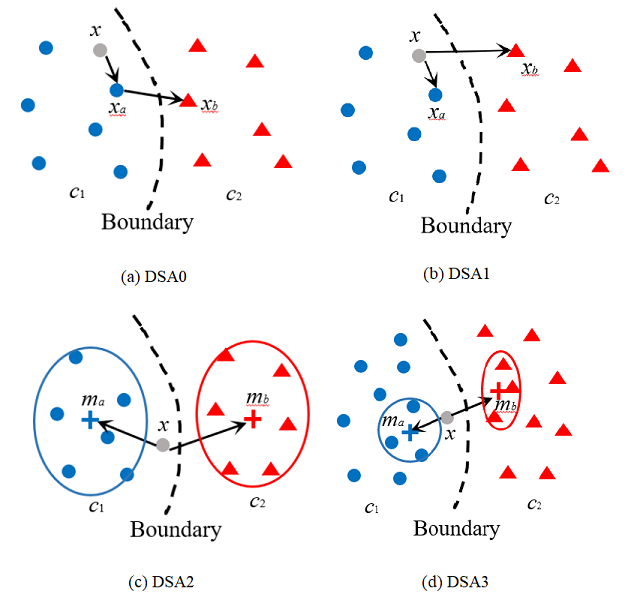
Corner case data description and detection
As the major factors affecting the safety of deep learning models, corner cases and related detection are crucial in AI quality assurance for constructing safety- and security-critical systems. The generic corner case researches involve two interesting topics. One is to enhance DL models robustness to corner case data via the adjustment on parameters/structure. The other is to generate new corner cases for model retraining and improvement. However, the complex architecture and the huge amount of parameters make the robust adjustment of DL models not easy, meanwhile it is not possible to generate all real-world corner cases for DL training. Therefore, this paper proposes to a simple and novel study aiming at corner case data detection via a specific metric. This metric is developed on surprise adequacy (SA) which has advantages on capture data behaviors. Furthermore, targeting at characteristics of corner case data, three modifications on distanced-based SA are developed for classification applications in this paper. Consequently, through the experiment analysis on MNIST data and industrial data, the feasibility and usefulness of the proposed method on corner case data detection are verified.
PDF Abstract
 MNIST
MNIST
