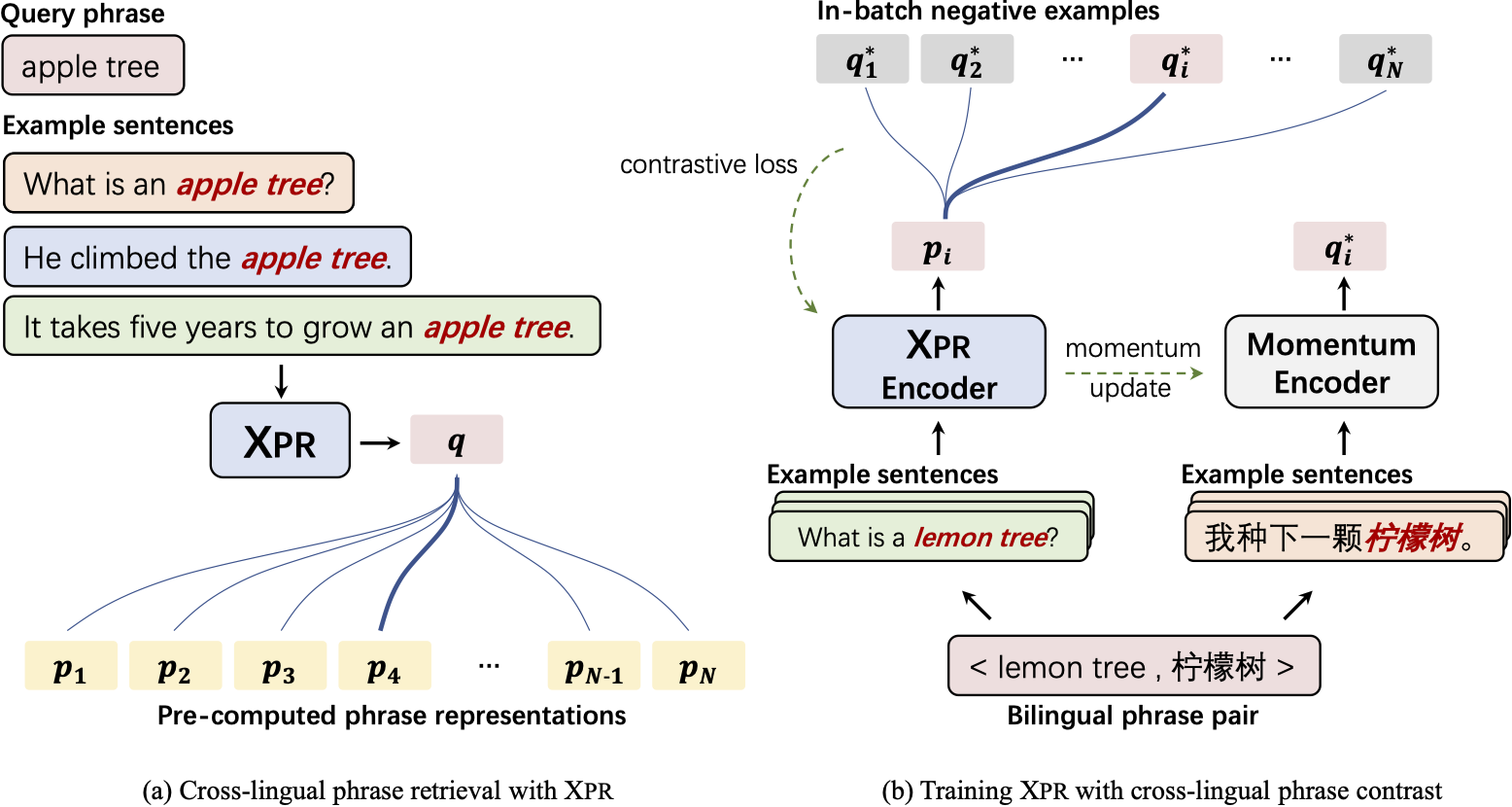
Cross-Lingual Phrase Retrieval
Cross-lingual retrieval aims to retrieve relevant text across languages. Current methods typically achieve cross-lingual retrieval by learning language-agnostic text representations in word or sentence level. However, how to learn phrase representations for cross-lingual phrase retrieval is still an open problem. In this paper, we propose XPR, a cross-lingual phrase retriever that extracts phrase representations from unlabeled example sentences. Moreover, we create a large-scale cross-lingual phrase retrieval dataset, which contains 65K bilingual phrase pairs and 4.2M example sentences in 8 English-centric language pairs. Experimental results show that XPR outperforms state-of-the-art baselines which utilize word-level or sentence-level representations. XPR also shows impressive zero-shot transferability that enables the model to perform retrieval in an unseen language pair during training. Our dataset, code, and trained models are publicly available at www.github.com/cwszz/XPR/.
PDF Abstract ACL 2022 PDF ACL 2022 Abstract

