Cross-Modal Information-Guided Network using Contrastive Learning for Point Cloud Registration
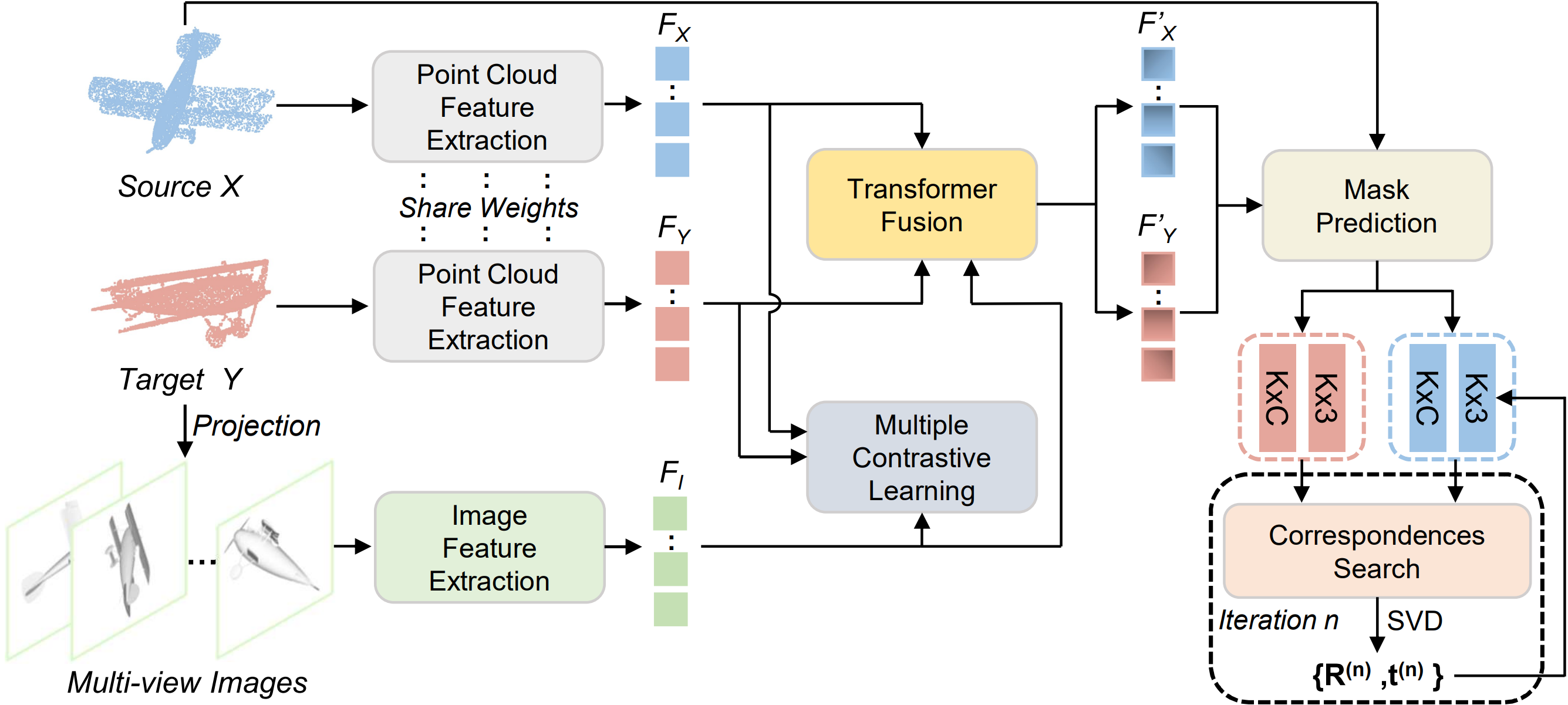
The majority of point cloud registration methods currently rely on extracting features from points. However, these methods are limited by their dependence on information obtained from a single modality of points, which can result in deficiencies such as inadequate perception of global features and a lack of texture information. Actually, humans can employ visual information learned from 2D images to comprehend the 3D world. Based on this fact, we present a novel Cross-Modal Information-Guided Network (CMIGNet), which obtains global shape perception through cross-modal information to achieve precise and robust point cloud registration. Specifically, we first incorporate the projected images from the point clouds and fuse the cross-modal features using the attention mechanism. Furthermore, we employ two contrastive learning strategies, namely overlapping contrastive learning and cross-modal contrastive learning. The former focuses on features in overlapping regions, while the latter emphasizes the correspondences between 2D and 3D features. Finally, we propose a mask prediction module to identify keypoints in the point clouds. Extensive experiments on several benchmark datasets demonstrate that our network achieves superior registration performance.
PDF Abstract


 ModelNet
ModelNet
