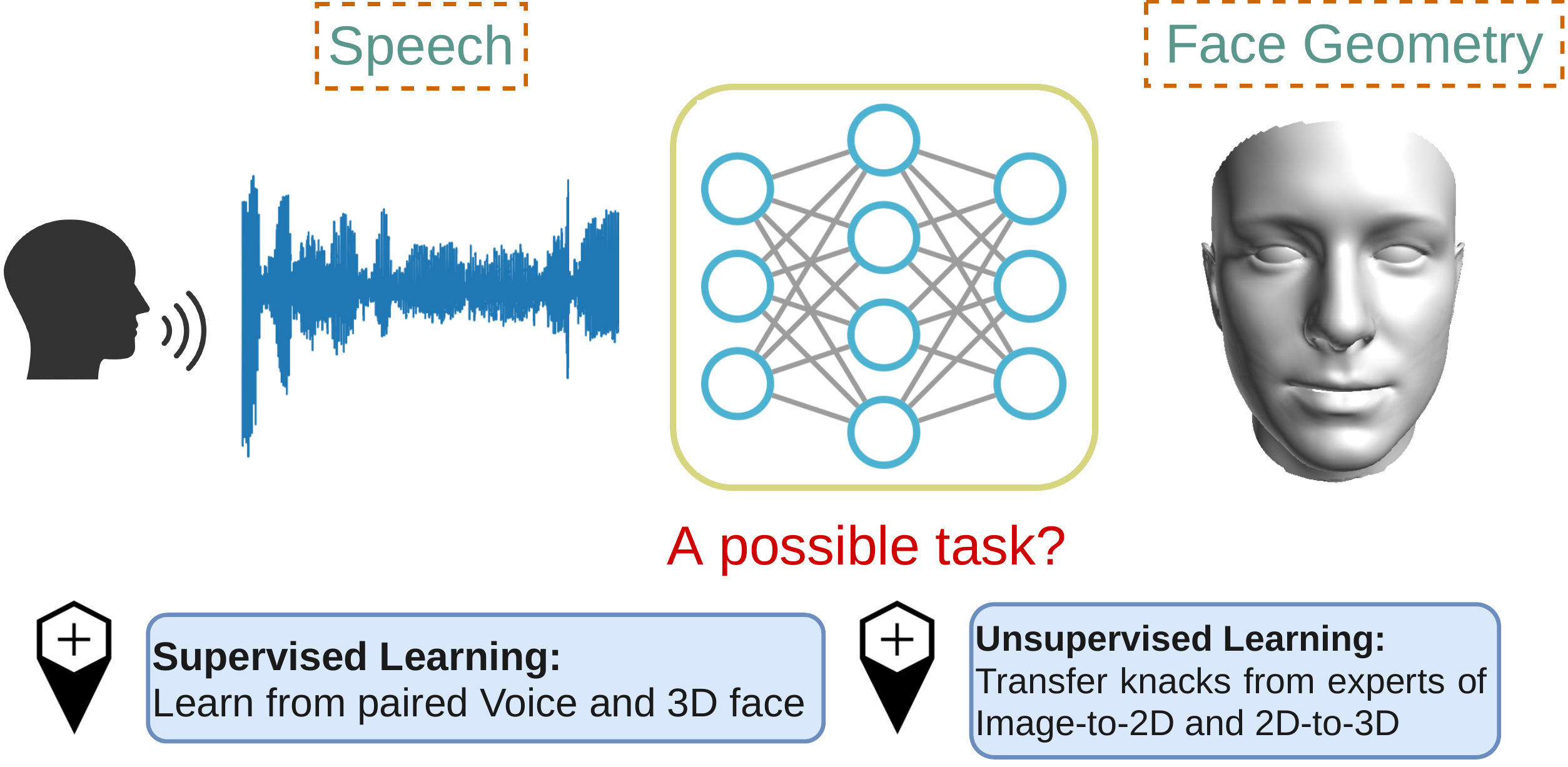
Cross-Modal Perceptionist: Can Face Geometry be Gleaned from Voices?
This work digs into a root question in human perception: can face geometry be gleaned from one's voices? Previous works that study this question only adopt developments in image synthesis and convert voices into face images to show correlations, but working on the image domain unavoidably involves predicting attributes that voices cannot hint, including facial textures, hairstyles, and backgrounds. We instead investigate the ability to reconstruct 3D faces to concentrate on only geometry, which is much more physiologically grounded. We propose our analysis framework, Cross-Modal Perceptionist, under both supervised and unsupervised learning. First, we construct a dataset, Voxceleb-3D, which extends Voxceleb and includes paired voices and face meshes, making supervised learning possible. Second, we use a knowledge distillation mechanism to study whether face geometry can still be gleaned from voices without paired voices and 3D face data under limited availability of 3D face scans. We break down the core question into four parts and perform visual and numerical analyses as responses to the core question. Our findings echo those in physiology and neuroscience about the correlation between voices and facial structures. The work provides future human-centric cross-modal learning with explainable foundations. See our project page: https://choyingw.github.io/works/Voice2Mesh/index.html
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract



 Voxceleb-3D
Voxceleb-3D
 VoxCeleb1
VoxCeleb1

