Cross-Modal Retrieval for Motion and Text via DopTriple Loss
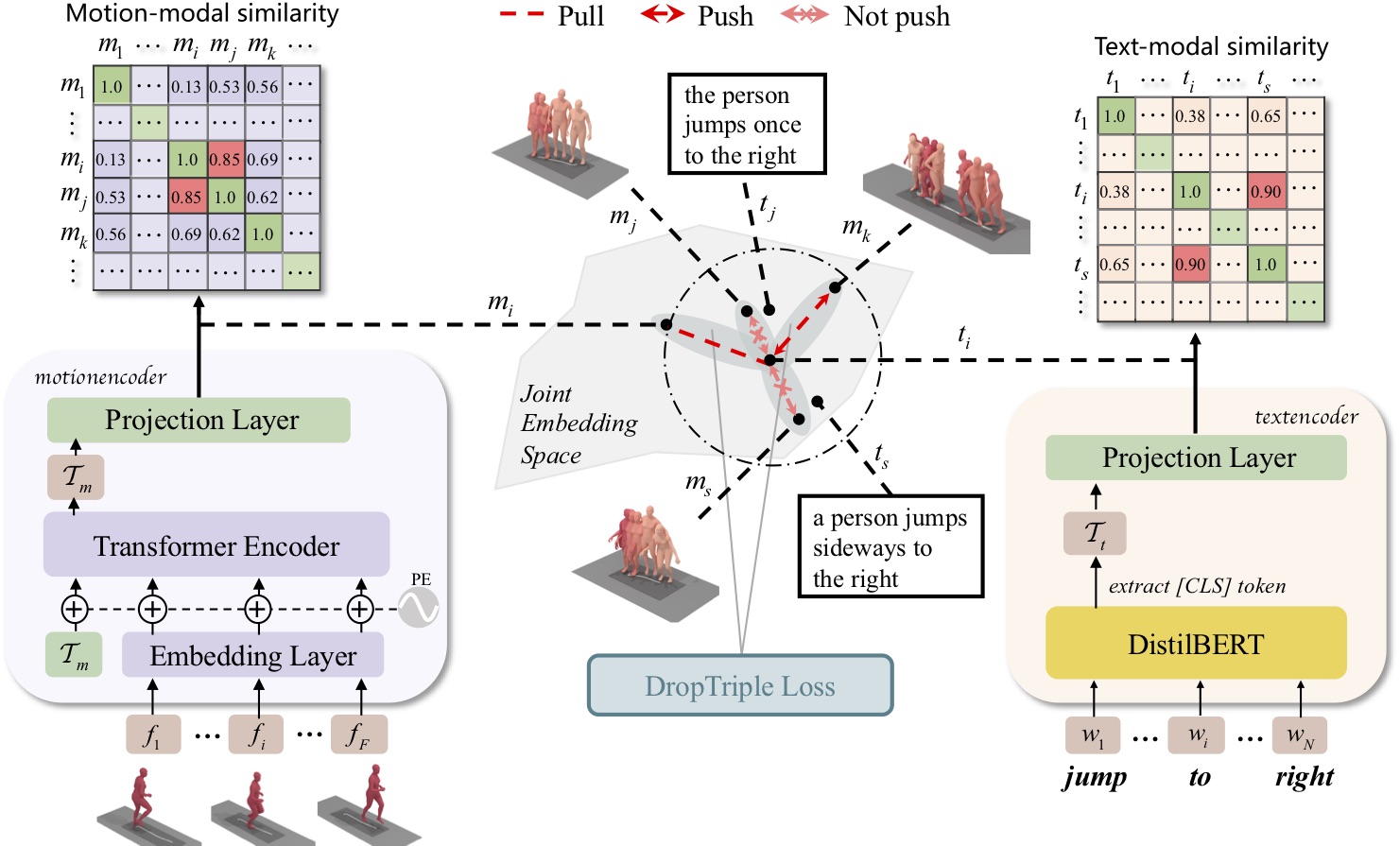
Cross-modal retrieval of image-text and video-text is a prominent research area in computer vision and natural language processing. However, there has been insufficient attention given to cross-modal retrieval between human motion and text, despite its wide-ranging applicability. To address this gap, we utilize a concise yet effective dual-unimodal transformer encoder for tackling this task. Recognizing that overlapping atomic actions in different human motion sequences can lead to semantic conflicts between samples, we explore a novel triplet loss function called DropTriple Loss. This loss function discards false negative samples from the negative sample set and focuses on mining remaining genuinely hard negative samples for triplet training, thereby reducing violations they cause. We evaluate our model and approach on the HumanML3D and KIT Motion-Language datasets. On the latest HumanML3D dataset, we achieve a recall of 62.9% for motion retrieval and 71.5% for text retrieval (both based on R@10). The source code for our approach is publicly available at https://github.com/eanson023/rehamot.
PDF Abstract

 HumanML3D
HumanML3D
