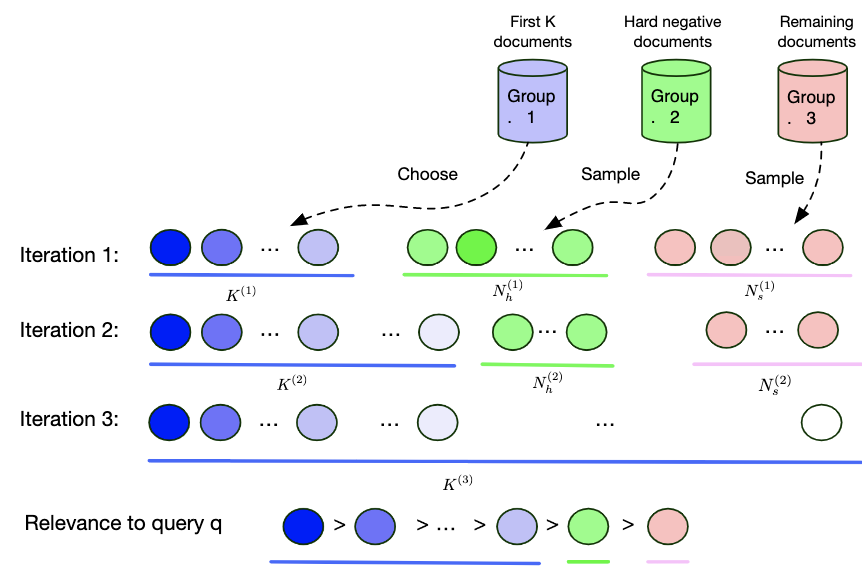
Curriculum Learning for Dense Retrieval Distillation
Recent work has shown that more effective dense retrieval models can be obtained by distilling ranking knowledge from an existing base re-ranking model. In this paper, we propose a generic curriculum learning based optimization framework called CL-DRD that controls the difficulty level of training data produced by the re-ranking (teacher) model. CL-DRD iteratively optimizes the dense retrieval (student) model by increasing the difficulty of the knowledge distillation data made available to it. In more detail, we initially provide the student model coarse-grained preference pairs between documents in the teacher's ranking and progressively move towards finer-grained pairwise document ordering requirements. In our experiments, we apply a simple implementation of the CL-DRD framework to enhance two state-of-the-art dense retrieval models. Experiments on three public passage retrieval datasets demonstrate the effectiveness of our proposed framework.
PDF Abstract

 MS MARCO
MS MARCO
