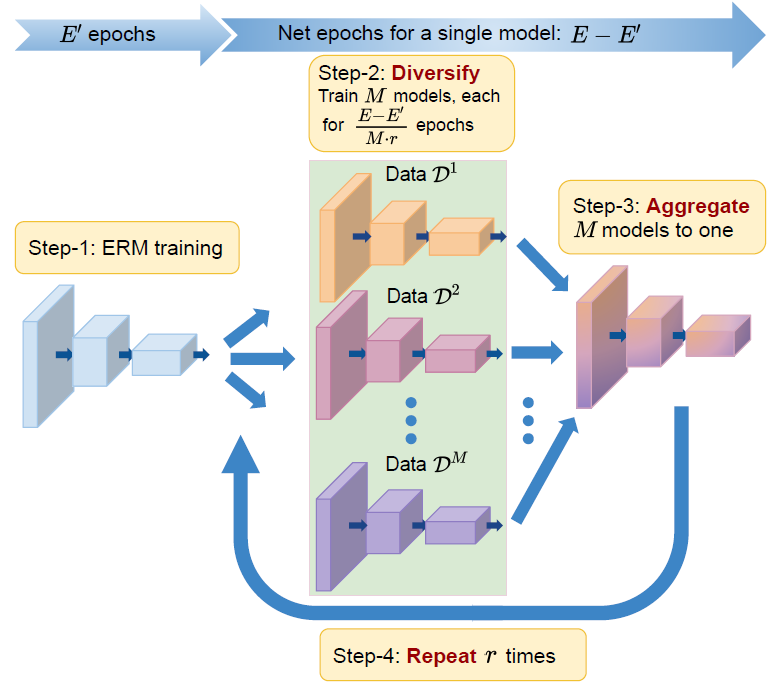
DART: Diversify-Aggregate-Repeat Training Improves Generalization of Neural Networks
Generalization of neural networks is crucial for deploying them safely in the real world. Common training strategies to improve generalization involve the use of data augmentations, ensembling and model averaging. In this work, we first establish a surprisingly simple but strong benchmark for generalization which utilizes diverse augmentations within a training minibatch, and show that this can learn a more balanced distribution of features. Further, we propose Diversify-Aggregate-Repeat Training (DART) strategy that first trains diverse models using different augmentations (or domains) to explore the loss basin, and further Aggregates their weights to combine their expertise and obtain improved generalization. We find that Repeating the step of Aggregation throughout training improves the overall optimization trajectory and also ensures that the individual models have a sufficiently low loss barrier to obtain improved generalization on combining them. We shed light on our approach by casting it in the framework proposed by Shen et al. and theoretically show that it indeed generalizes better. In addition to improvements in In- Domain generalization, we demonstrate SOTA performance on the Domain Generalization benchmarks in the popular DomainBed framework as well. Our method is generic and can easily be integrated with several base training algorithms to achieve performance gains.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract

 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 Office-Home
Office-Home
 Stanford Cars
Stanford Cars
 DomainNet
DomainNet
 PACS
PACS
