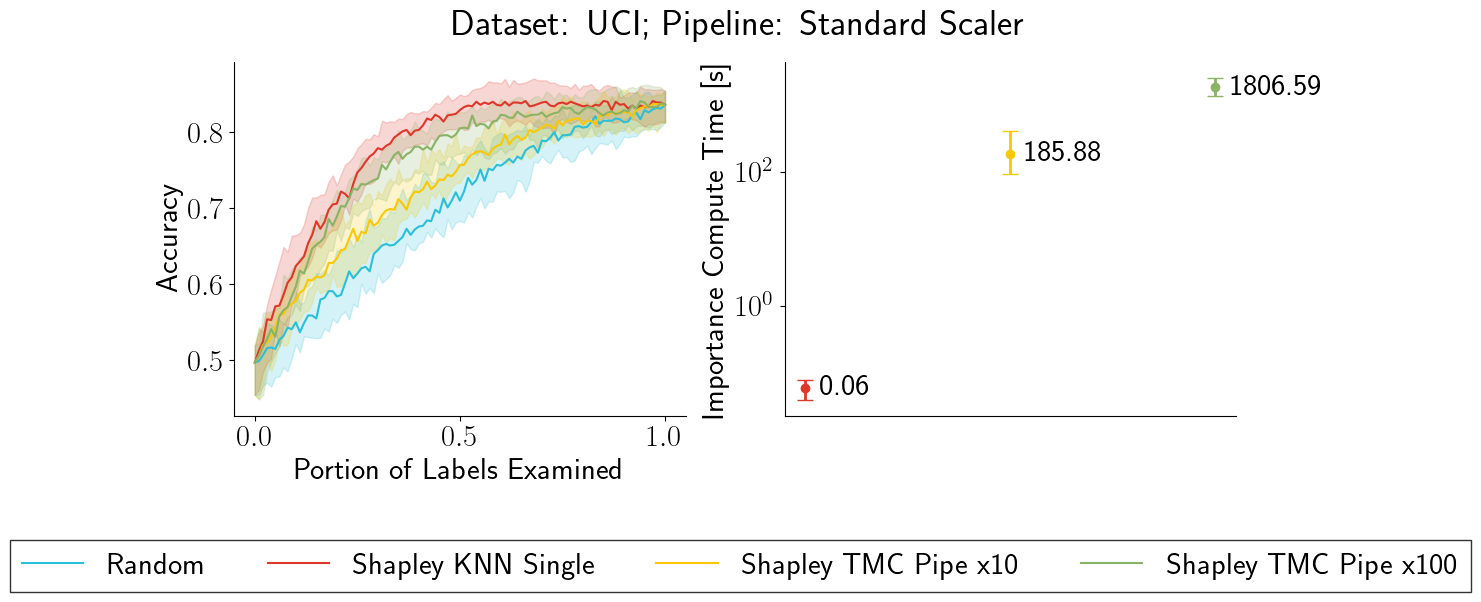
Data Debugging with Shapley Importance over End-to-End Machine Learning Pipelines
Developing modern machine learning (ML) applications is data-centric, of which one fundamental challenge is to understand the influence of data quality to ML training -- "Which training examples are 'guilty' in making the trained ML model predictions inaccurate or unfair?" Modeling data influence for ML training has attracted intensive interest over the last decade, and one popular framework is to compute the Shapley value of each training example with respect to utilities such as validation accuracy and fairness of the trained ML model. Unfortunately, despite recent intensive interest and research, existing methods only consider a single ML model "in isolation" and do not consider an end-to-end ML pipeline that consists of data transformations, feature extractors, and ML training. We present DataScope (ease.ml/datascope), the first system that efficiently computes Shapley values of training examples over an end-to-end ML pipeline, and illustrate its applications in data debugging for ML training. To this end, we first develop a novel algorithmic framework that computes Shapley value over a specific family of ML pipelines that we call canonical pipelines: a positive relational algebra query followed by a K-nearest-neighbor (KNN) classifier. We show that, for many subfamilies of canonical pipelines, computing Shapley value is in PTIME, contrasting the exponential complexity of computing Shapley value in general. We then put this to practice -- given an sklearn pipeline, we approximate it with a canonical pipeline to use as a proxy. We conduct extensive experiments illustrating different use cases and utilities. Our results show that DataScope is up to four orders of magnitude faster over state-of-the-art Monte Carlo-based methods, while being comparably, and often even more, effective in data debugging.
PDF Abstract Colab
Colab


 Fashion-MNIST
Fashion-MNIST
