Deconstruct to Reconstruct a Configurable Evaluation Metric for Open-Domain Dialogue Systems
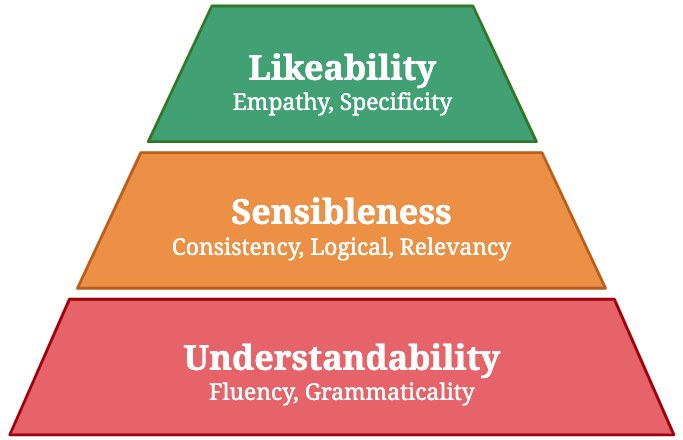
Many automatic evaluation metrics have been proposed to score the overall quality of a response in open-domain dialogue. Generally, the overall quality is comprised of various aspects, such as relevancy, specificity, and empathy, and the importance of each aspect differs according to the task. For instance, specificity is mandatory in a food-ordering dialogue task, whereas fluency is preferred in a language-teaching dialogue system. However, existing metrics are not designed to cope with such flexibility. For example, BLEU score fundamentally relies only on word overlapping, whereas BERTScore relies on semantic similarity between reference and candidate response. Thus, they are not guaranteed to capture the required aspects, i.e., specificity. To design a metric that is flexible to a task, we first propose making these qualities manageable by grouping them into three groups: understandability, sensibleness, and likability, where likability is a combination of qualities that are essential for a task. We also propose a simple method to composite metrics of each aspect to obtain a single metric called USL-H, which stands for Understandability, Sensibleness, and Likability in Hierarchy. We demonstrated that USL-H score achieves good correlations with human judgment and maintains its configurability towards different aspects and metrics.
PDF Abstract COLING 2020 PDF COLING 2020 Abstract


 DailyDialog
DailyDialog
