Deep attractor network for single-microphone speaker separation
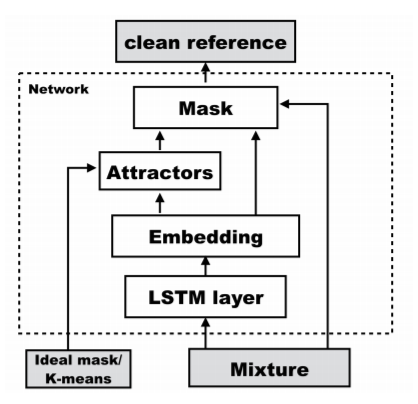
Despite the overwhelming success of deep learning in various speech processing tasks, the problem of separating simultaneous speakers in a mixture remains challenging. Two major difficulties in such systems are the arbitrary source permutation and unknown number of sources in the mixture. We propose a novel deep learning framework for single channel speech separation by creating attractor points in high dimensional embedding space of the acoustic signals which pull together the time-frequency bins corresponding to each source. Attractor points in this study are created by finding the centroids of the sources in the embedding space, which are subsequently used to determine the similarity of each bin in the mixture to each source. The network is then trained to minimize the reconstruction error of each source by optimizing the embeddings. The proposed model is different from prior works in that it implements an end-to-end training, and it does not depend on the number of sources in the mixture. Two strategies are explored in the test time, K-means and fixed attractor points, where the latter requires no post-processing and can be implemented in real-time. We evaluated our system on Wall Street Journal dataset and show 5.49\% improvement over the previous state-of-the-art methods.
PDF Abstract Colab
Colab



