Deep Learning under Privileged Information Using Heteroscedastic Dropout
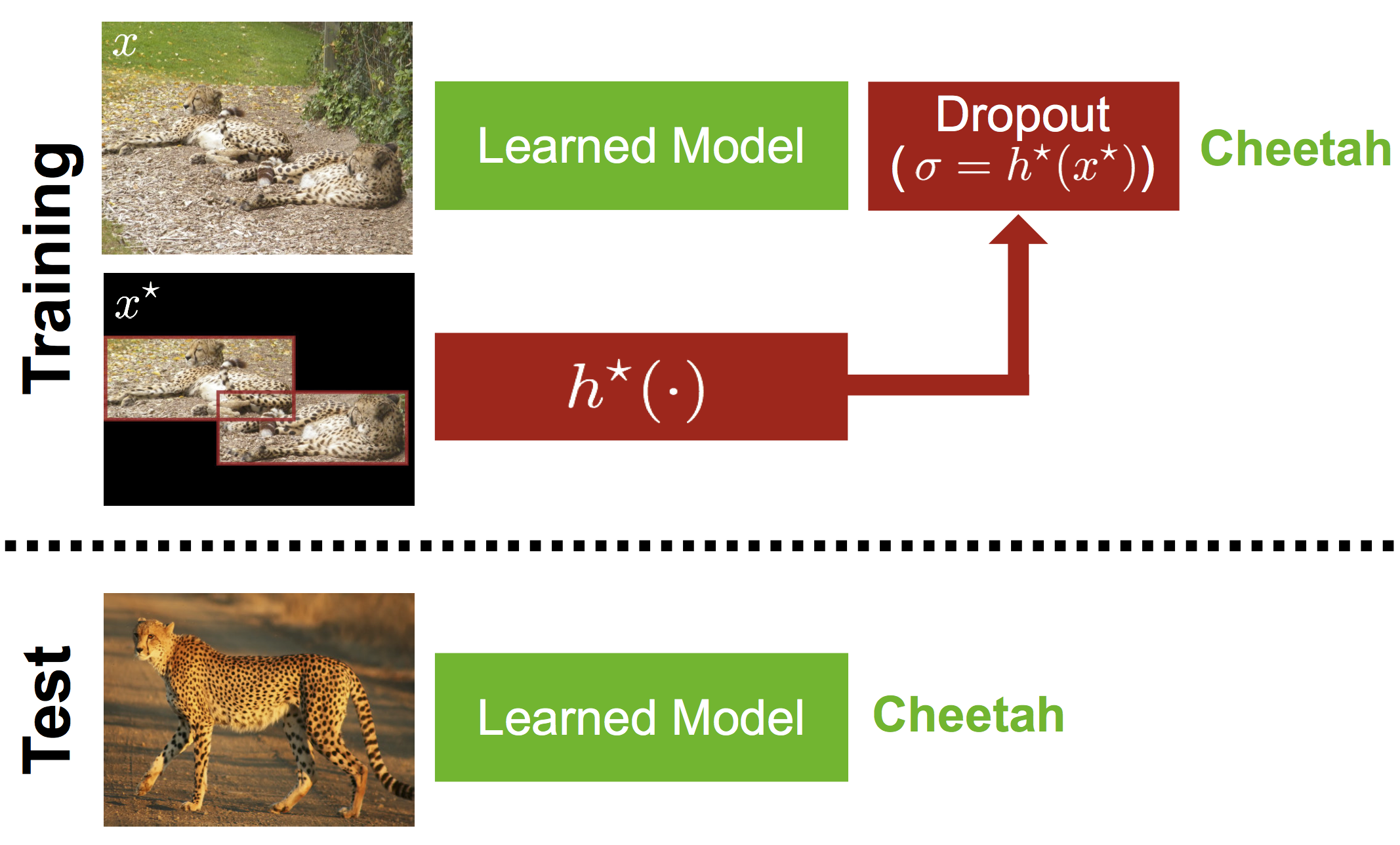
Unlike machines, humans learn through rapid, abstract model-building. The role of a teacher is not simply to hammer home right or wrong answers, but rather to provide intuitive comments, comparisons, and explanations to a pupil. This is what the Learning Under Privileged Information (LUPI) paradigm endeavors to model by utilizing extra knowledge only available during training. We propose a new LUPI algorithm specifically designed for Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). We propose to use a heteroscedastic dropout (i.e. dropout with a varying variance) and make the variance of the dropout a function of privileged information. Intuitively, this corresponds to using the privileged information to control the uncertainty of the model output. We perform experiments using CNNs and RNNs for the tasks of image classification and machine translation. Our method significantly increases the sample efficiency during learning, resulting in higher accuracy with a large margin when the number of training examples is limited. We also theoretically justify the gains in sample efficiency by providing a generalization error bound decreasing with $O(\frac{1}{n})$, where $n$ is the number of training examples, in an oracle case.
PDF Abstract CVPR 2018 PDF CVPR 2018 Abstract



 ImageNet
ImageNet
