Detecting Hallucinated Content in Conditional Neural Sequence Generation
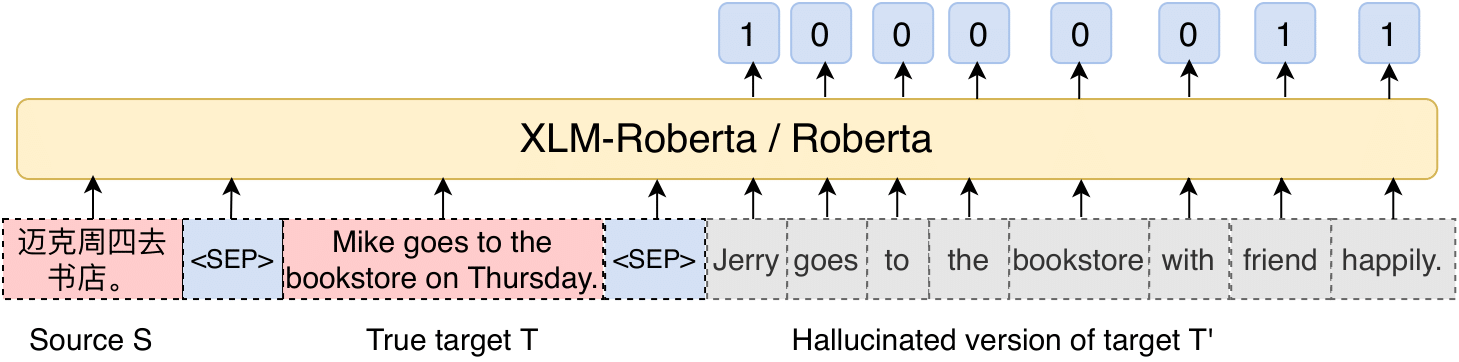
Neural sequence models can generate highly fluent sentences, but recent studies have also shown that they are also prone to hallucinate additional content not supported by the input. These variety of fluent but wrong outputs are particularly problematic, as it will not be possible for users to tell they are being presented incorrect content. To detect these errors, we propose a task to predict whether each token in the output sequence is hallucinated (not contained in the input) and collect new manually annotated evaluation sets for this task. We also introduce a method for learning to detect hallucinations using pretrained language models fine tuned on synthetic data that includes automatically inserted hallucinations Experiments on machine translation (MT) and abstractive summarization demonstrate that our proposed approach consistently outperforms strong baselines on all benchmark datasets. We further demonstrate how to use the token-level hallucination labels to define a fine-grained loss over the target sequence in low-resource MT and achieve significant improvements over strong baseline methods. We also apply our method to word-level quality estimation for MT and show its effectiveness in both supervised and unsupervised settings. Codes and data available at https://github.com/violet-zct/fairseq-detect-hallucination.
PDF Abstract Findings (ACL) 2021 PDF Findings (ACL) 2021 Abstract




 FLoRes
FLoRes
