DIANet: Dense-and-Implicit Attention Network
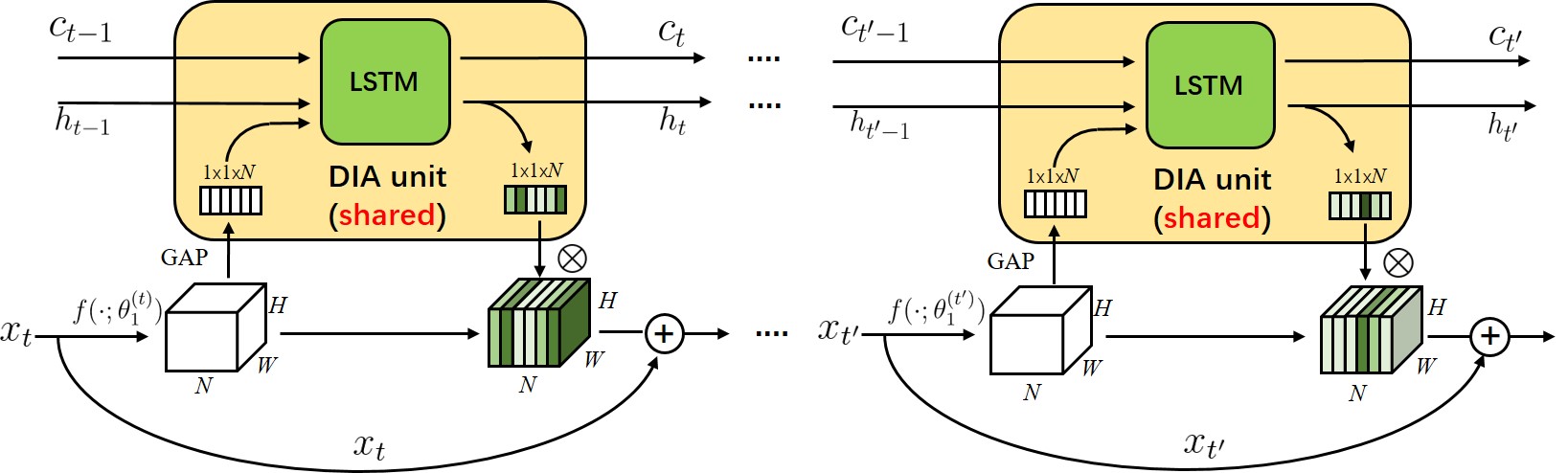
Attention networks have successfully boosted the performance in various vision problems. Previous works lay emphasis on designing a new attention module and individually plug them into the networks. Our paper proposes a novel-and-simple framework that shares an attention module throughout different network layers to encourage the integration of layer-wise information and this parameter-sharing module is referred as Dense-and-Implicit-Attention (DIA) unit. Many choices of modules can be used in the DIA unit. Since Long Short Term Memory (LSTM) has a capacity of capturing long-distance dependency, we focus on the case when the DIA unit is the modified LSTM (refer as DIA-LSTM). Experiments on benchmark datasets show that the DIA-LSTM unit is capable of emphasizing layer-wise feature interrelation and leads to significant improvement of image classification accuracy. We further empirically show that the DIA-LSTM has a strong regularization ability on stabilizing the training of deep networks by the experiments with the removal of skip connections or Batch Normalization in the whole residual network. The code is released at https://github.com/gbup-group/DIANet.
PDF AbstractCode


Tasks

 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
Results from the Paper
 Ranked #139 on
Image Classification
on CIFAR-100
(using extra training data)
Ranked #139 on
Image Classification
on CIFAR-100
(using extra training data)
