Direct Speech-to-image Translation
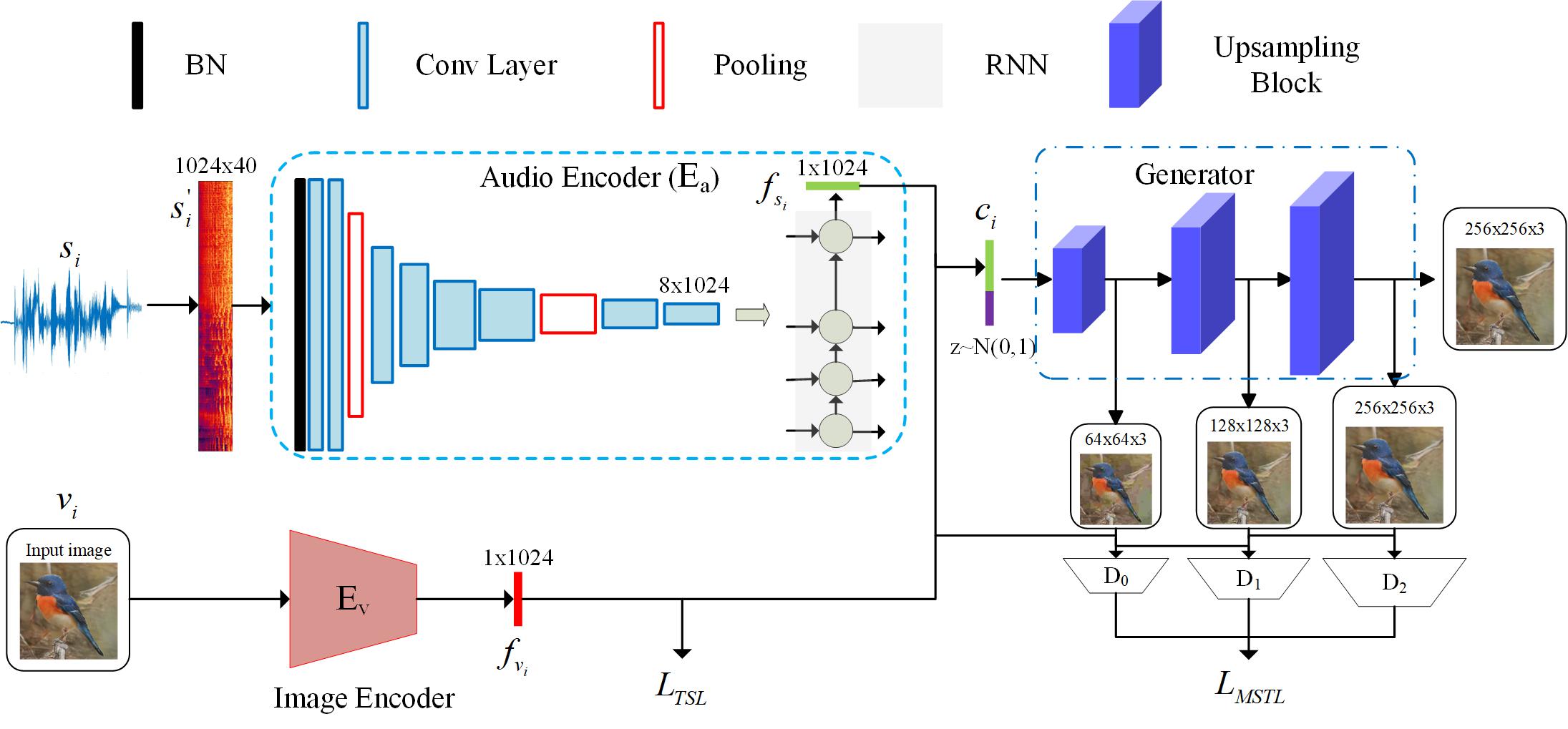
Direct speech-to-image translation without text is an interesting and useful topic due to the potential applications in human-computer interaction, art creation, computer-aided design. etc. Not to mention that many languages have no writing form. However, as far as we know, it has not been well-studied how to translate the speech signals into images directly and how well they can be translated. In this paper, we attempt to translate the speech signals into the image signals without the transcription stage. Specifically, a speech encoder is designed to represent the input speech signals as an embedding feature, and it is trained with a pretrained image encoder using teacher-student learning to obtain better generalization ability on new classes. Subsequently, a stacked generative adversarial network is used to synthesize high-quality images conditioned on the embedding feature. Experimental results on both synthesized and real data show that our proposed method is effective to translate the raw speech signals into images without the middle text representation. Ablation study gives more insights about our method.
PDF Abstract
 ImageNet
ImageNet
 MS COCO
MS COCO
 CUB-200-2011
CUB-200-2011
 Places205
Places205
