Distribution-Aware Prompt Tuning for Vision-Language Models
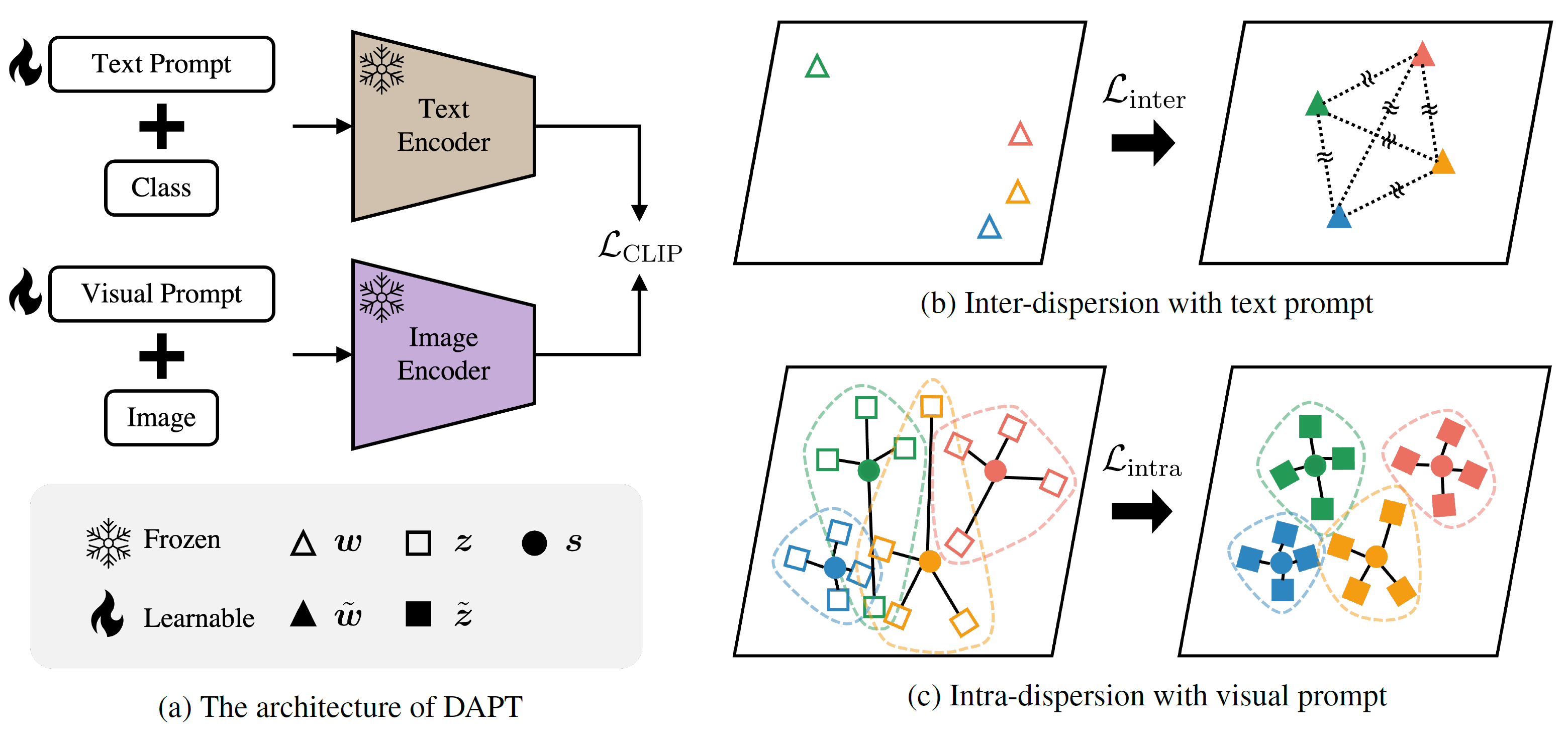
Pre-trained vision-language models (VLMs) have shown impressive performance on various downstream tasks by utilizing knowledge learned from large data. In general, the performance of VLMs on target tasks can be further improved by prompt tuning, which adds context to the input image or text. By leveraging data from target tasks, various prompt-tuning methods have been studied in the literature. A key to prompt tuning is the feature space alignment between two modalities via learnable vectors with model parameters fixed. We observed that the alignment becomes more effective when embeddings of each modality are `well-arranged' in the latent space. Inspired by this observation, we proposed distribution-aware prompt tuning (DAPT) for vision-language models, which is simple yet effective. Specifically, the prompts are learned by maximizing inter-dispersion, the distance between classes, as well as minimizing the intra-dispersion measured by the distance between embeddings from the same class. Our extensive experiments on 11 benchmark datasets demonstrate that our method significantly improves generalizability. The code is available at https://github.com/mlvlab/DAPT.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract
 ImageNet
ImageNet
 UCF101
UCF101
 Oxford 102 Flower
Oxford 102 Flower
 Stanford Cars
Stanford Cars
 DTD
DTD
 Food-101
Food-101
 Caltech-101
Caltech-101
 EuroSAT
EuroSAT
 FGVC-Aircraft
FGVC-Aircraft
 ImageNet-R
ImageNet-R
 ImageNet-A
ImageNet-A
 ImageNet-Sketch
ImageNet-Sketch
