DuReader_retrieval: A Large-scale Chinese Benchmark for Passage Retrieval from Web Search Engine
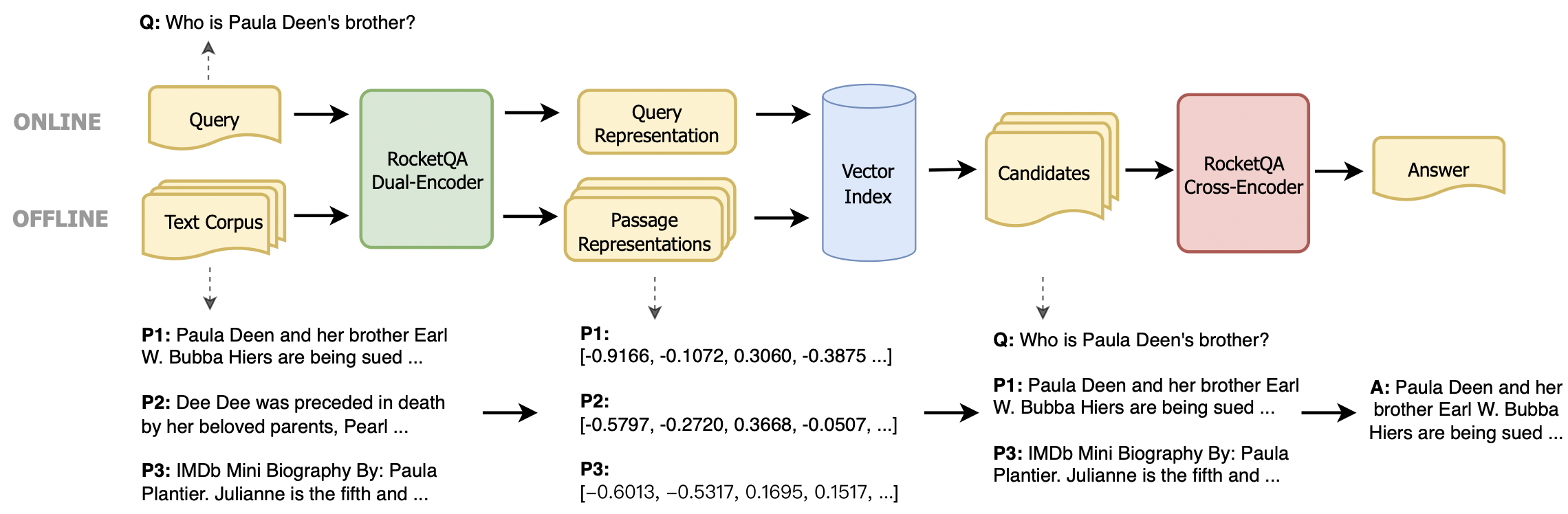
In this paper, we present DuReader_retrieval, a large-scale Chinese dataset for passage retrieval. DuReader_retrieval contains more than 90K queries and over 8M unique passages from a commercial search engine. To alleviate the shortcomings of other datasets and ensure the quality of our benchmark, we (1) reduce the false negatives in development and test sets by manually annotating results pooled from multiple retrievers, and (2) remove the training queries that are semantically similar to the development and testing queries. Additionally, we provide two out-of-domain testing sets for cross-domain evaluation, as well as a set of human translated queries for for cross-lingual retrieval evaluation. The experiments demonstrate that DuReader_retrieval is challenging and a number of problems remain unsolved, such as the salient phrase mismatch and the syntactic mismatch between queries and paragraphs. These experiments also show that dense retrievers do not generalize well across domains, and cross-lingual retrieval is essentially challenging. DuReader_retrieval is publicly available at https://github.com/baidu/DuReader/tree/master/DuReader-Retrieval.
PDF AbstractCode



Datasets
Introduced in the Paper:
cCOVID-NewsUsed in the Paper:
 Natural Questions
Natural Questions
 MS MARCO
MS MARCO
 TriviaQA
TriviaQA
 DuReader
DuReader
