Efficient and Flexible Topic Modeling using Pretrained Embeddings and Bag of Sentences
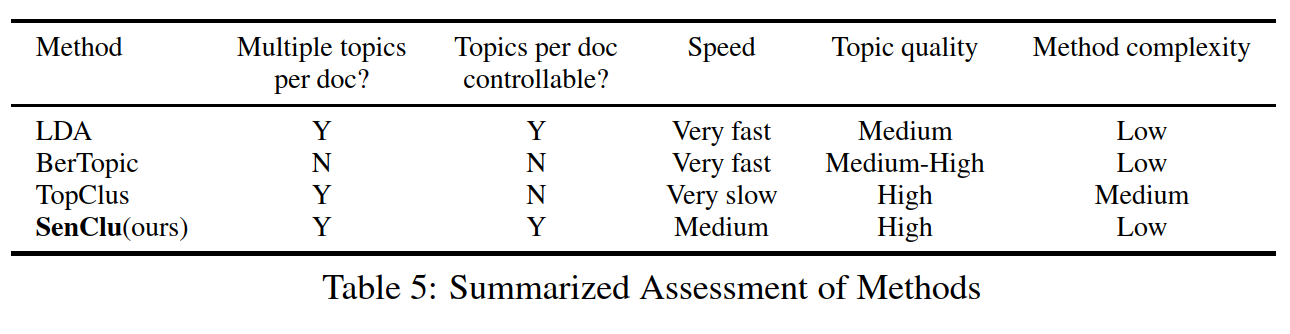
Pre-trained language models have led to a new state-of-the-art in many NLP tasks. However, for topic modeling, statistical generative models such as LDA are still prevalent, which do not easily allow incorporating contextual word vectors. They might yield topics that do not align well with human judgment. In this work, we propose a novel topic modeling and inference algorithm. We suggest a bag of sentences (BoS) approach using sentences as the unit of analysis. We leverage pre-trained sentence embeddings by combining generative process models and clustering. We derive a fast inference algorithm based on expectation maximization, hard assignments, and an annealing process. The evaluation shows that our method yields state-of-the art results with relatively little computational demands. Our method is also more flexible compared to prior works leveraging word embeddings, since it provides the possibility to customize topic-document distributions using priors. Code and data is at \url{https://github.com/JohnTailor/BertSenClu}.
PDF Abstract


