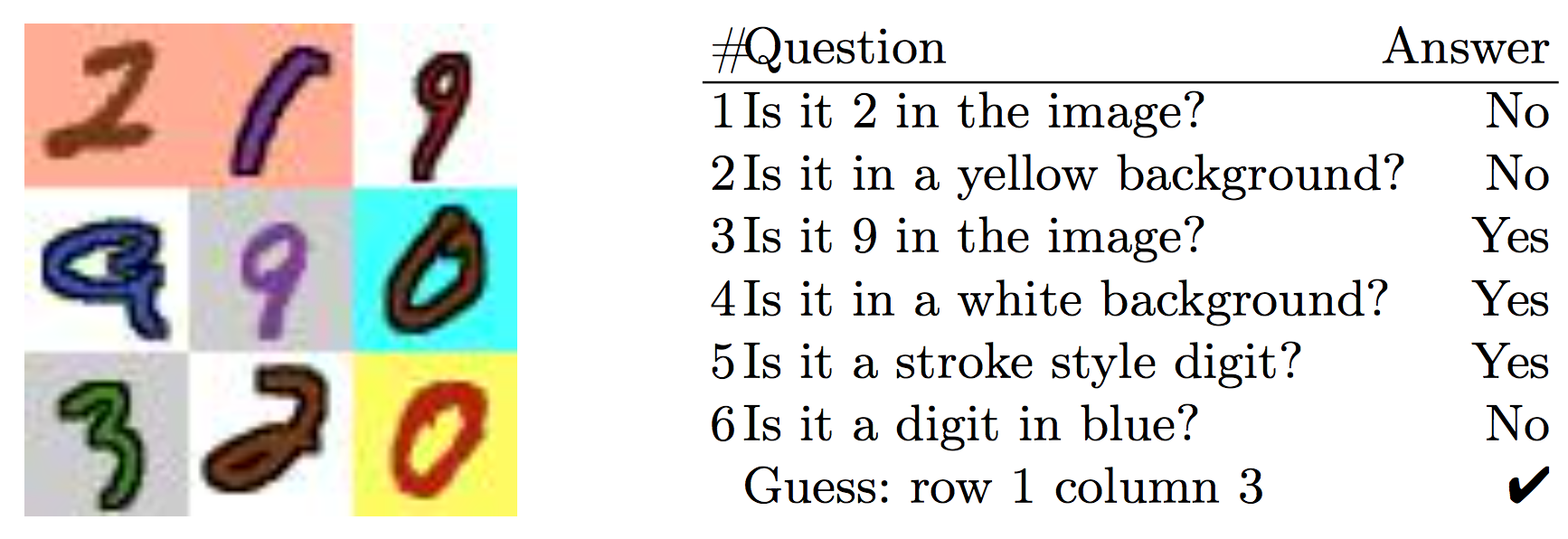
Efficient Dialog Policy Learning via Positive Memory Retention
This paper is concerned with the training of recurrent neural networks as goal-oriented dialog agents using reinforcement learning. Training such agents with policy gradients typically requires a large amount of samples. However, the collection of the required data in form of conversations between chat-bots and human agents is time-consuming and expensive. To mitigate this problem, we describe an efficient policy gradient method using positive memory retention, which significantly increases the sample-efficiency. We show that our method is 10 times more sample-efficient than policy gradients in extensive experiments on a new synthetic number guessing game. Moreover, in a real-word visual object discovery game, the proposed method is twice as sample-efficient as policy gradients and shows state-of-the-art performance.
PDF Abstract

