Efficient Learning of Minimax Risk Classifiers in High Dimensions
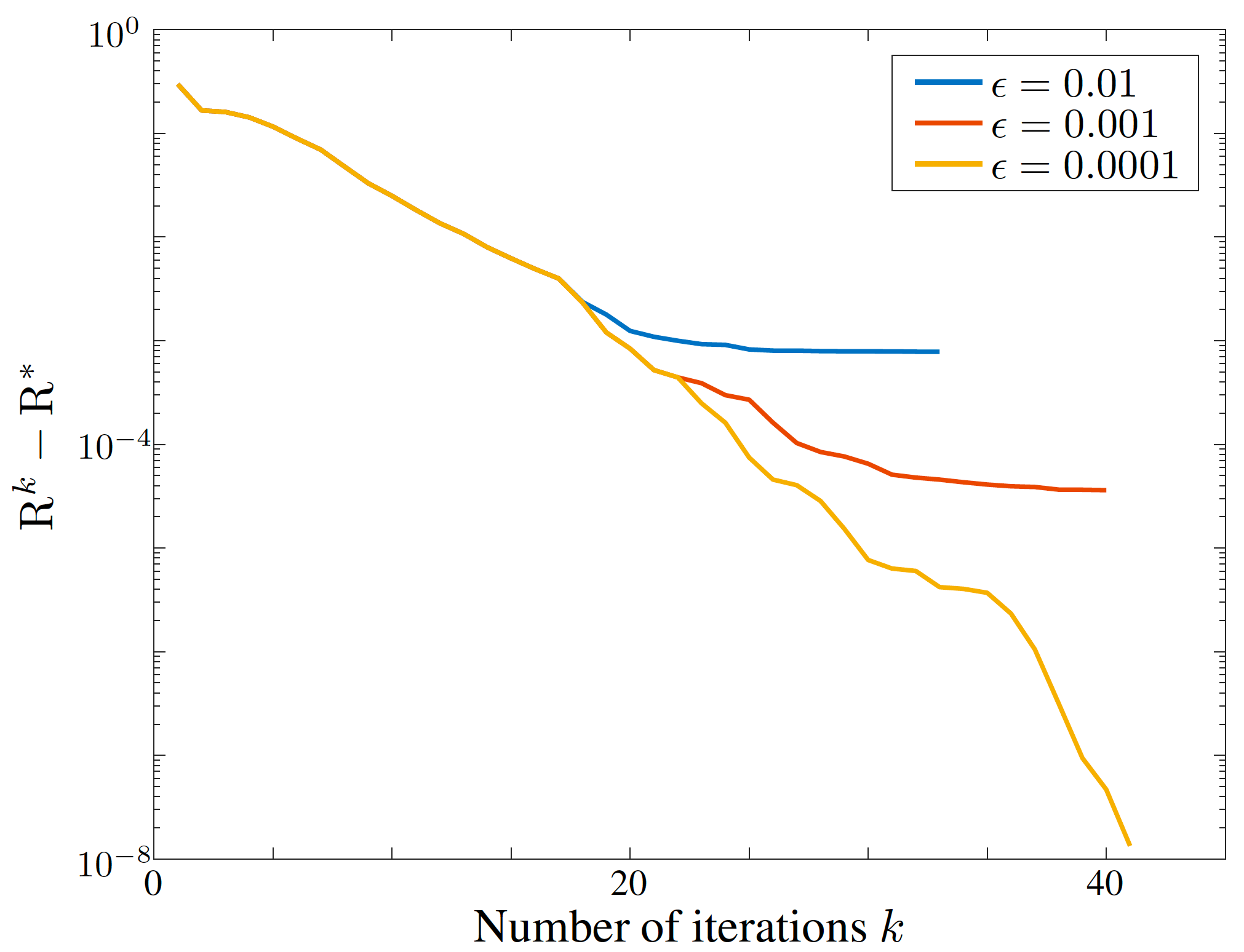
High-dimensional data is common in multiple areas, such as health care and genomics, where the number of features can be tens of thousands. In such scenarios, the large number of features often leads to inefficient learning. Constraint generation methods have recently enabled efficient learning of L1-regularized support vector machines (SVMs). In this paper, we leverage such methods to obtain an efficient learning algorithm for the recently proposed minimax risk classifiers (MRCs). The proposed iterative algorithm also provides a sequence of worst-case error probabilities and performs feature selection. Experiments on multiple high-dimensional datasets show that the proposed algorithm is efficient in high-dimensional scenarios. In addition, the worst-case error probability provides useful information about the classifier performance, and the features selected by the algorithm are competitive with the state-of-the-art.
PDF Abstract
