Efficient Probabilistic Performance Bounds for Inverse Reinforcement Learning
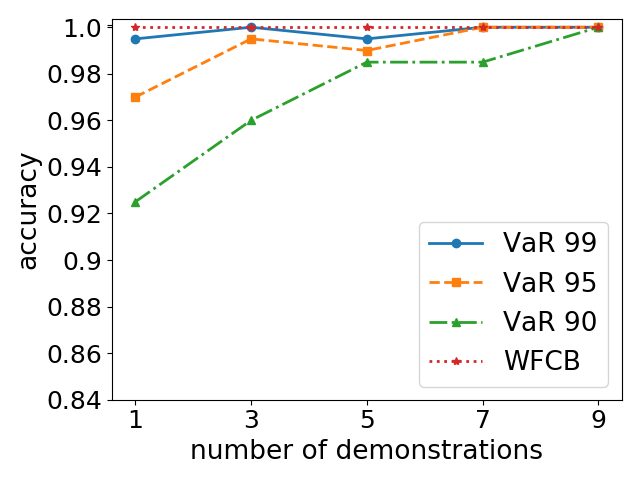
In the field of reinforcement learning there has been recent progress towards safety and high-confidence bounds on policy performance. However, to our knowledge, no practical methods exist for determining high-confidence policy performance bounds in the inverse reinforcement learning setting---where the true reward function is unknown and only samples of expert behavior are given. We propose a sampling method based on Bayesian inverse reinforcement learning that uses demonstrations to determine practical high-confidence upper bounds on the $\alpha$-worst-case difference in expected return between any evaluation policy and the optimal policy under the expert's unknown reward function. We evaluate our proposed bound on both a standard grid navigation task and a simulated driving task and achieve tighter and more accurate bounds than a feature count-based baseline. We also give examples of how our proposed bound can be utilized to perform risk-aware policy selection and risk-aware policy improvement. Because our proposed bound requires several orders of magnitude fewer demonstrations than existing high-confidence bounds, it is the first practical method that allows agents that learn from demonstration to express confidence in the quality of their learned policy.
PDF Abstract
