Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer
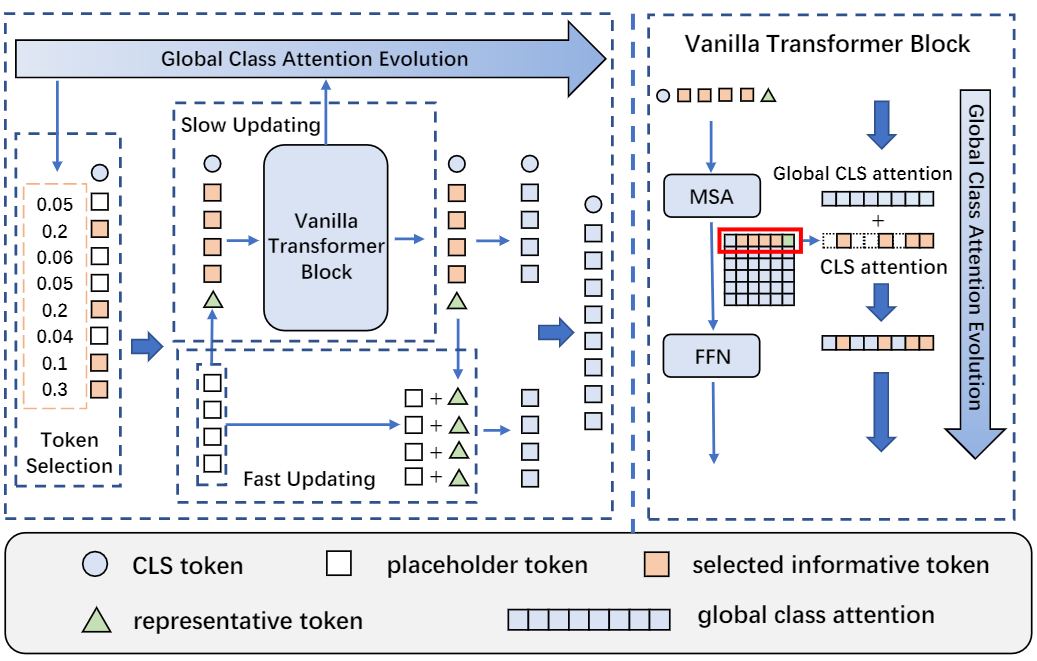
Vision transformers (ViTs) have recently received explosive popularity, but the huge computational cost is still a severe issue. Since the computation complexity of ViT is quadratic with respect to the input sequence length, a mainstream paradigm for computation reduction is to reduce the number of tokens. Existing designs include structured spatial compression that uses a progressive shrinking pyramid to reduce the computations of large feature maps, and unstructured token pruning that dynamically drops redundant tokens. However, the limitation of existing token pruning lies in two folds: 1) the incomplete spatial structure caused by pruning is not compatible with structured spatial compression that is commonly used in modern deep-narrow transformers; 2) it usually requires a time-consuming pre-training procedure. To tackle the limitations and expand the applicable scenario of token pruning, we present Evo-ViT, a self-motivated slow-fast token evolution approach for vision transformers. Specifically, we conduct unstructured instance-wise token selection by taking advantage of the simple and effective global class attention that is native to vision transformers. Then, we propose to update the selected informative tokens and uninformative tokens with different computation paths, namely, slow-fast updating. Since slow-fast updating mechanism maintains the spatial structure and information flow, Evo-ViT can accelerate vanilla transformers of both flat and deep-narrow structures from the very beginning of the training process. Experimental results demonstrate that our method significantly reduces the computational cost of vision transformers while maintaining comparable performance on image classification.
PDF Abstract


 ImageNet
ImageNet

