Exploring Format Consistency for Instruction Tuning
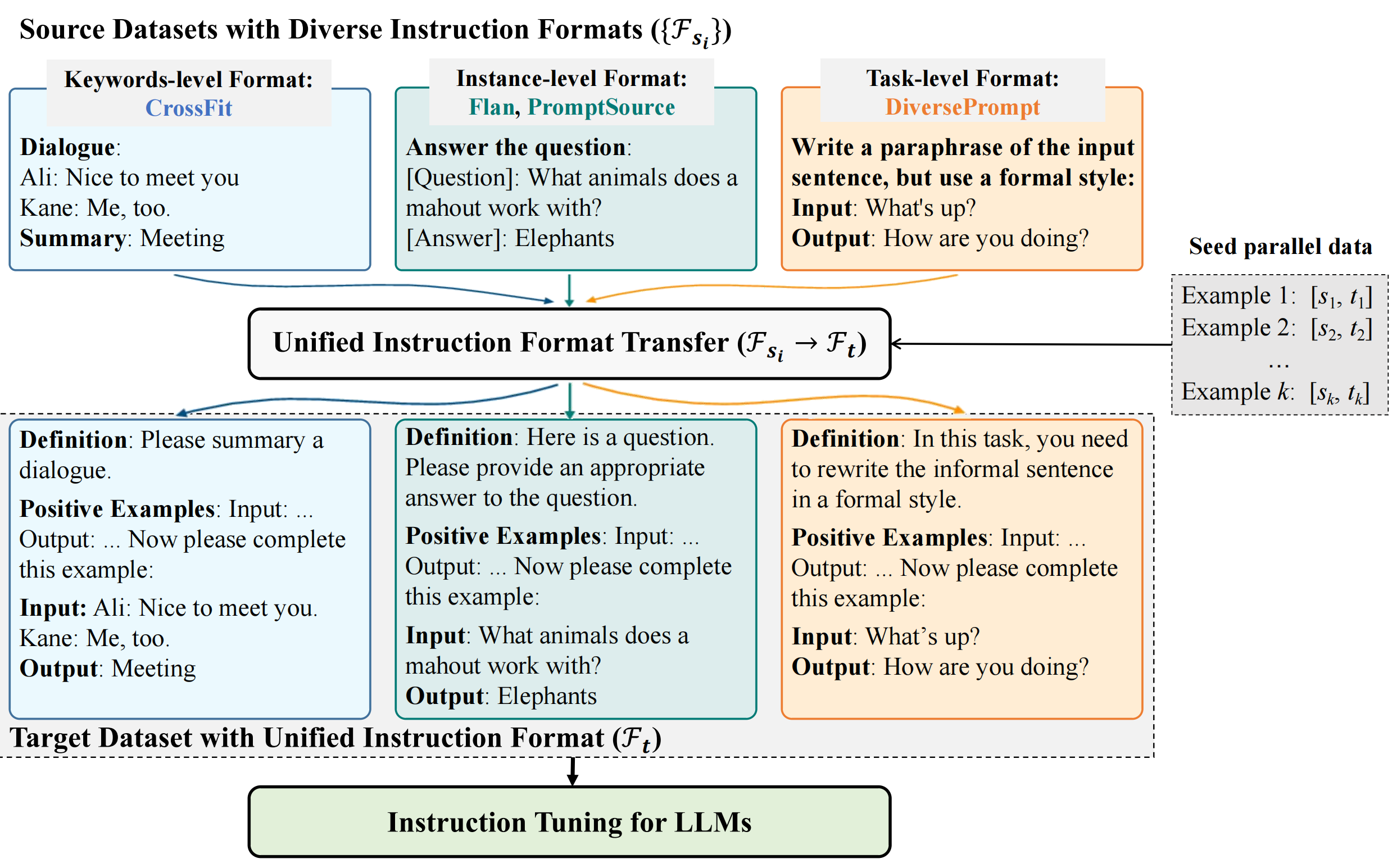
Instruction tuning has emerged as a promising approach to enhancing large language models in following human instructions. It is shown that increasing the diversity and number of instructions in the training data can consistently enhance generalization performance, which facilitates a recent endeavor to collect various instructions and integrate existing instruction tuning datasets into larger collections. However, different users have their unique ways of expressing instructions, and there often exist variations across different datasets in the instruction styles and formats, i.e., format inconsistency. In this work, we propose a framework named Unified Instruction Tuning (UIT), which calls OpenAI APIs for automatic format transfer among different instruction tuning datasets such as PromptSource, FLAN and CrossFit. With the framework, we (1) demonstrate the necessity of maintaining format consistency in instruction tuning; (2) improve the generalization performance on unseen instructions on T5-LM-xl; (3) provide a novel perplexity-based denoising method to reduce the noise of automatic format transfer to make the UIT framework more practical and a smaller offline model based on GPT-J that achieves comparable format transfer capability to OpenAI APIs to reduce costs in practice. Further analysis regarding variations of targeted formats and other effects is intended.
PDF Abstract

