FairNeuron: Improving Deep Neural Network Fairness with Adversary Games on Selective Neurons
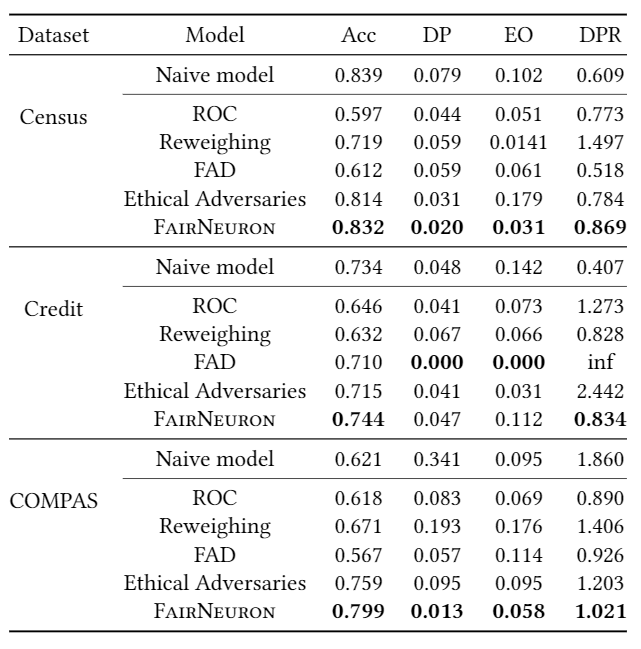
With Deep Neural Network (DNN) being integrated into a growing number of critical systems with far-reaching impacts on society, there are increasing concerns on their ethical performance, such as fairness. Unfortunately, model fairness and accuracy in many cases are contradictory goals to optimize. To solve this issue, there has been a number of work trying to improve model fairness by using an adversarial game in model level. This approach introduces an adversary that evaluates the fairness of a model besides its prediction accuracy on the main task, and performs joint-optimization to achieve a balanced result. In this paper, we noticed that when performing backward propagation based training, such contradictory phenomenon has shown on individual neuron level. Based on this observation, we propose FairNeuron, a DNN model automatic repairing tool, to mitigate fairness concerns and balance the accuracy-fairness trade-off without introducing another model. It works on detecting neurons with contradictory optimization directions from accuracy and fairness training goals, and achieving a trade-off by selective dropout. Comparing with state-of-the-art methods, our approach is lightweight, making it scalable and more efficient. Our evaluation on 3 datasets shows that FairNeuron can effectively improve all models' fairness while maintaining a stable utility.
PDF Abstract

 Adult
Adult
