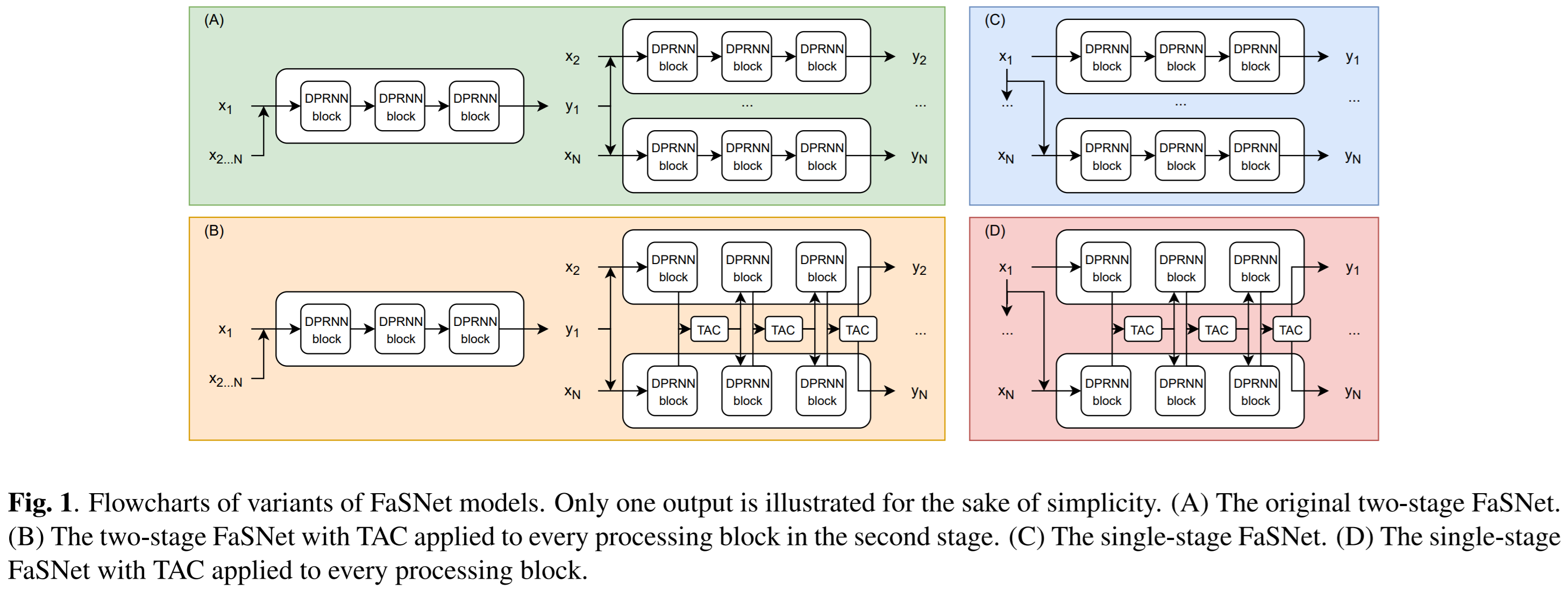
FaSNet: Low-latency Adaptive Beamforming for Multi-microphone Audio Processing
Beamforming has been extensively investigated for multi-channel audio processing tasks. Recently, learning-based beamforming methods, sometimes called \textit{neural beamformers}, have achieved significant improvements in both signal quality (e.g. signal-to-noise ratio (SNR)) and speech recognition (e.g. word error rate (WER)). Such systems are generally non-causal and require a large context for robust estimation of inter-channel features, which is impractical in applications requiring low-latency responses. In this paper, we propose filter-and-sum network (FaSNet), a time-domain, filter-based beamforming approach suitable for low-latency scenarios. FaSNet has a two-stage system design that first learns frame-level time-domain adaptive beamforming filters for a selected reference channel, and then calculate the filters for all remaining channels. The filtered outputs at all channels are summed to generate the final output. Experiments show that despite its small model size, FaSNet is able to outperform several traditional oracle beamformers with respect to scale-invariant signal-to-noise ratio (SI-SNR) in reverberant speech enhancement and separation tasks. Moreover, when trained with a frequency-domain objective function on the CHiME-3 dataset, FaSNet achieves 14.3\% relative word error rate reduction (RWERR) compared with the baseline model. These results show the efficacy of FaSNet particularly in reverberant and noisy signal conditions.
PDF Abstract



