Federated Learning on Non-IID Data Silos: An Experimental Study
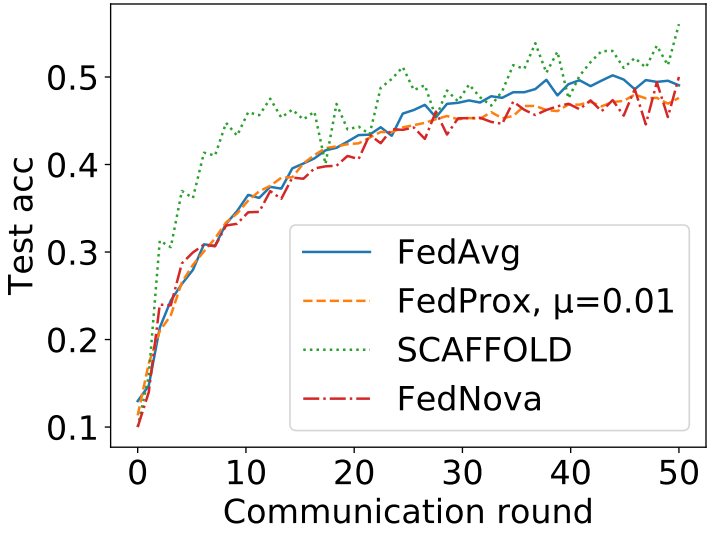
Due to the increasing privacy concerns and data regulations, training data have been increasingly fragmented, forming distributed databases of multiple "data silos" (e.g., within different organizations and countries). To develop effective machine learning services, there is a must to exploit data from such distributed databases without exchanging the raw data. Recently, federated learning (FL) has been a solution with growing interests, which enables multiple parties to collaboratively train a machine learning model without exchanging their local data. A key and common challenge on distributed databases is the heterogeneity of the data distribution among the parties. The data of different parties are usually non-independently and identically distributed (i.e., non-IID). There have been many FL algorithms to address the learning effectiveness under non-IID data settings. However, there lacks an experimental study on systematically understanding their advantages and disadvantages, as previous studies have very rigid data partitioning strategies among parties, which are hardly representative and thorough. In this paper, to help researchers better understand and study the non-IID data setting in federated learning, we propose comprehensive data partitioning strategies to cover the typical non-IID data cases. Moreover, we conduct extensive experiments to evaluate state-of-the-art FL algorithms. We find that non-IID does bring significant challenges in learning accuracy of FL algorithms, and none of the existing state-of-the-art FL algorithms outperforms others in all cases. Our experiments provide insights for future studies of addressing the challenges in "data silos".
PDF Abstract
 Colab
Colab


 CIFAR-10
CIFAR-10
 MNIST
MNIST
 SVHN
SVHN
