Federated Self-Training for Semi-Supervised Audio Recognition
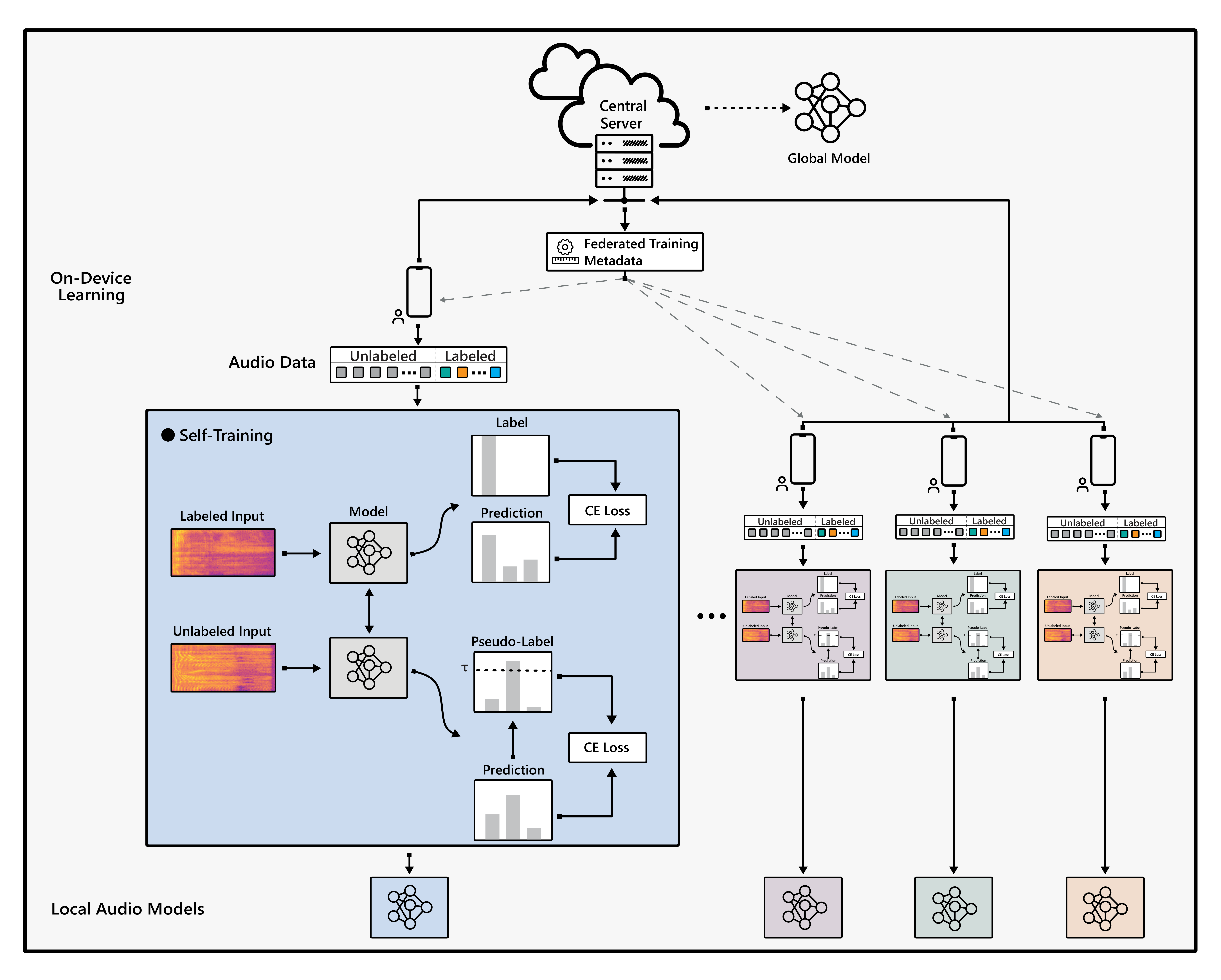
Federated Learning is a distributed machine learning paradigm dealing with decentralized and personal datasets. Since data reside on devices like smartphones and virtual assistants, labeling is entrusted to the clients, or labels are extracted in an automated way. Specifically, in the case of audio data, acquiring semantic annotations can be prohibitively expensive and time-consuming. As a result, an abundance of audio data remains unlabeled and unexploited on users' devices. Most existing federated learning approaches focus on supervised learning without harnessing the unlabeled data. In this work, we study the problem of semi-supervised learning of audio models via self-training in conjunction with federated learning. We propose FedSTAR to exploit large-scale on-device unlabeled data to improve the generalization of audio recognition models. We further demonstrate that self-supervised pre-trained models can accelerate the training of on-device models, significantly improving convergence to within fewer training rounds. We conduct experiments on diverse public audio classification datasets and investigate the performance of our models under varying percentages of labeled and unlabeled data. Notably, we show that with as little as 3% labeled data available, FedSTAR on average can improve the recognition rate by 13.28% compared to the fully supervised federated model.
PDF Abstract

 Speech Commands
Speech Commands
 FSD50K
FSD50K
