FedMAX: Mitigating Activation Divergence for Accurate and Communication-Efficient Federated Learning
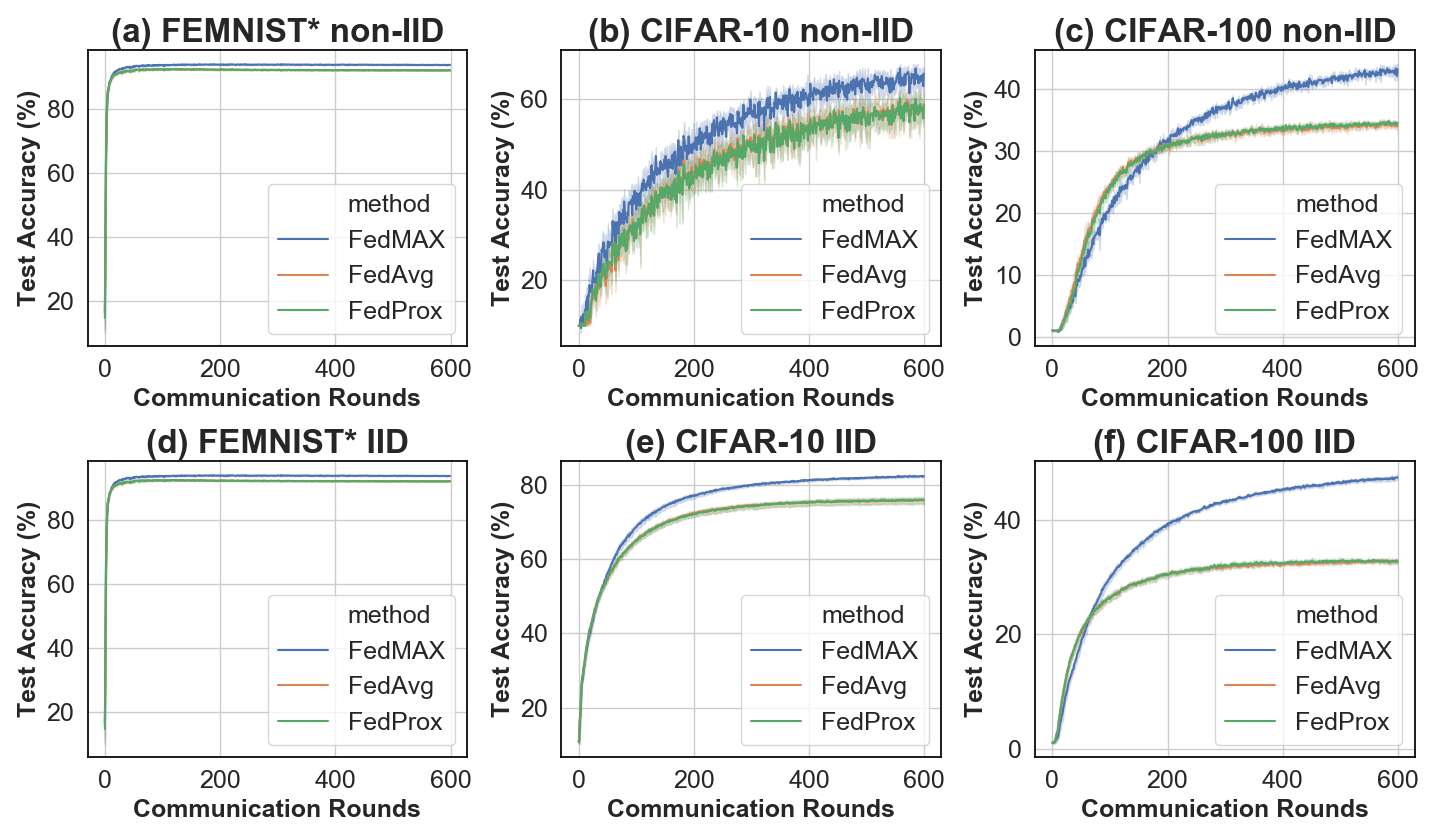
In this paper, we identify a new phenomenon called activation-divergence which occurs in Federated Learning (FL) due to data heterogeneity (i.e., data being non-IID) across multiple users. Specifically, we argue that the activation vectors in FL can diverge, even if subsets of users share a few common classes with data residing on different devices. To address the activation-divergence issue, we introduce a prior based on the principle of maximum entropy; this prior assumes minimal information about the per-device activation vectors and aims at making the activation vectors of same classes as similar as possible across multiple devices. Our results show that, for both IID and non-IID settings, our proposed approach results in better accuracy (due to the significantly more similar activation vectors across multiple devices), and is more communication-efficient than state-of-the-art approaches in FL. Finally, we illustrate the effectiveness of our approach on a few common benchmarks and two large medical datasets.
PDF Abstract

