Fine-tuning with Very Large Dropout
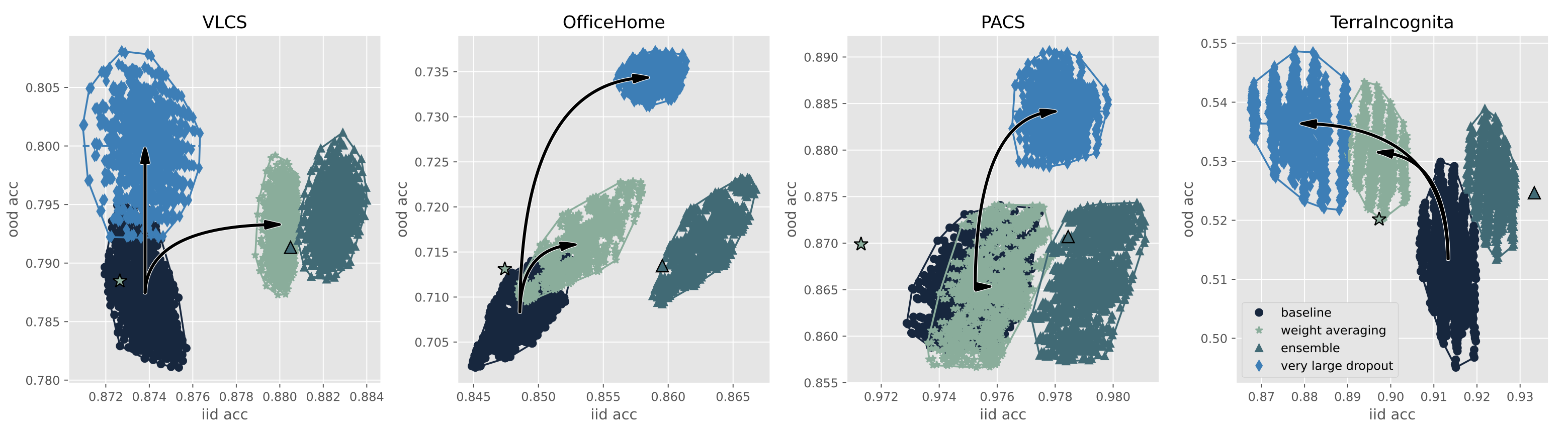
It is impossible today to pretend that the practice of machine learning is compatible with the idea that training and testing data follow the same distribution. Several authors have recently used ensemble techniques to show how scenarios involving multiple data distributions are best served by representations that are both richer than those obtained by regularizing for the best in-distribution performance, and richer than those obtained under the influence of the implicit sparsity bias of common stochastic gradient procedures. This contribution investigates the use of very high dropout rates instead of ensembles to obtain such rich representations. Although training a deep network from scratch using such dropout rates is virtually impossible, fine-tuning a large pre-trained model under such conditions is not only possible but also achieves out-of-distribution performances that exceed those of both ensembles and weight averaging methods such as model soups. This result has practical significance because the importance of the fine-tuning scenario has considerably grown in recent years. This result also provides interesting insights on the nature of rich representations and on the intrinsically linear nature of fine-tuning a large network using a comparatively small dataset.
PDF Abstract
 Office-Home
Office-Home
 DomainNet
DomainNet
 PACS
PACS
