First-Pass Large Vocabulary Continuous Speech Recognition using Bi-Directional Recurrent DNNs
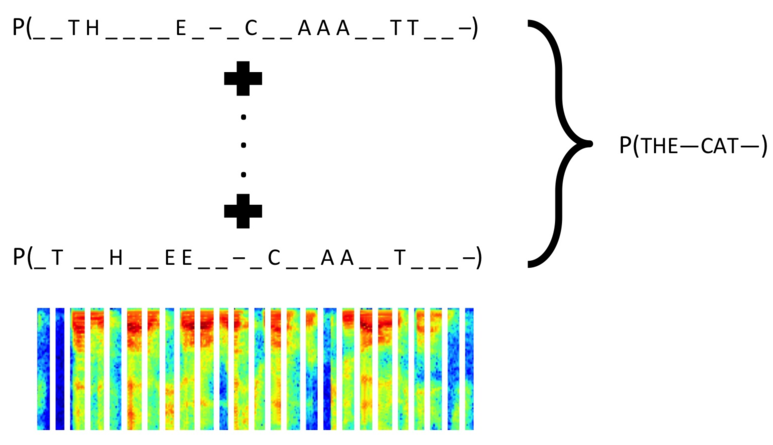
We present a method to perform first-pass large vocabulary continuous speech recognition using only a neural network and language model. Deep neural network acoustic models are now commonplace in HMM-based speech recognition systems, but building such systems is a complex, domain-specific task. Recent work demonstrated the feasibility of discarding the HMM sequence modeling framework by directly predicting transcript text from audio. This paper extends this approach in two ways. First, we demonstrate that a straightforward recurrent neural network architecture can achieve a high level of accuracy. Second, we propose and evaluate a modified prefix-search decoding algorithm. This approach to decoding enables first-pass speech recognition with a language model, completely unaided by the cumbersome infrastructure of HMM-based systems. Experiments on the Wall Street Journal corpus demonstrate fairly competitive word error rates, and the importance of bi-directional network recurrence.
PDF Abstract





