First Place Solution to the CVPR'2023 AQTC Challenge: A Function-Interaction Centric Approach with Spatiotemporal Visual-Language Alignment
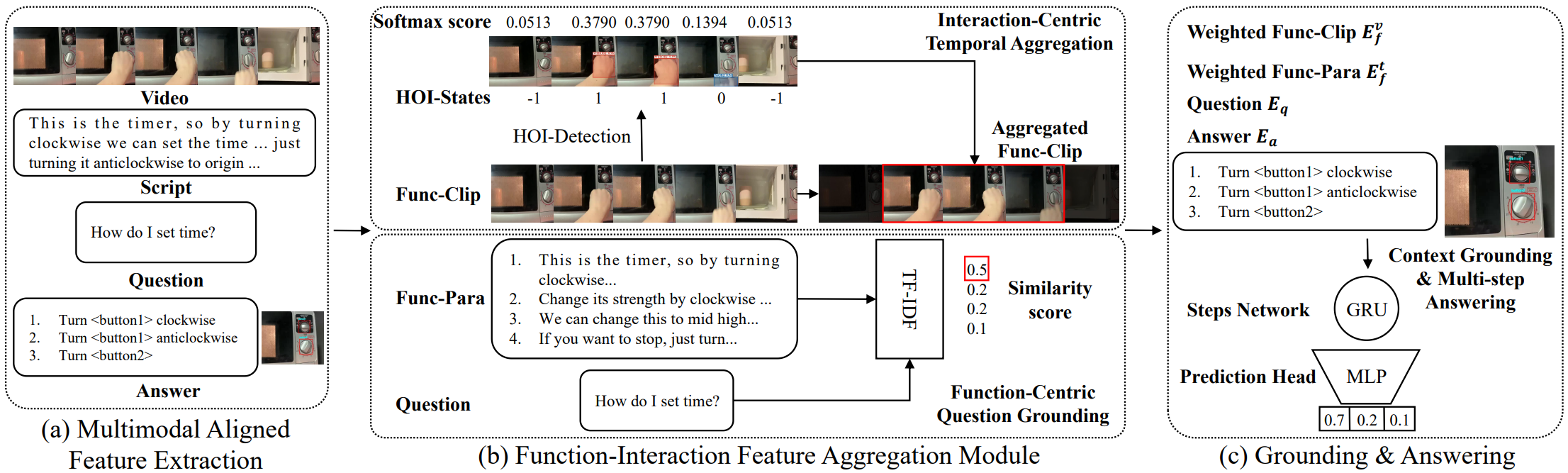
Affordance-Centric Question-driven Task Completion (AQTC) has been proposed to acquire knowledge from videos to furnish users with comprehensive and systematic instructions. However, existing methods have hitherto neglected the necessity of aligning spatiotemporal visual and linguistic signals, as well as the crucial interactional information between humans and objects. To tackle these limitations, we propose to combine large-scale pre-trained vision-language and video-language models, which serve to contribute stable and reliable multimodal data and facilitate effective spatiotemporal visual-textual alignment. Additionally, a novel hand-object-interaction (HOI) aggregation module is proposed which aids in capturing human-object interaction information, thereby further augmenting the capacity to understand the presented scenario. Our method achieved first place in the CVPR'2023 AQTC Challenge, with a Recall@1 score of 78.7\%. The code is available at https://github.com/tomchen-ctj/CVPR23-LOVEU-AQTC.
PDF Abstract

