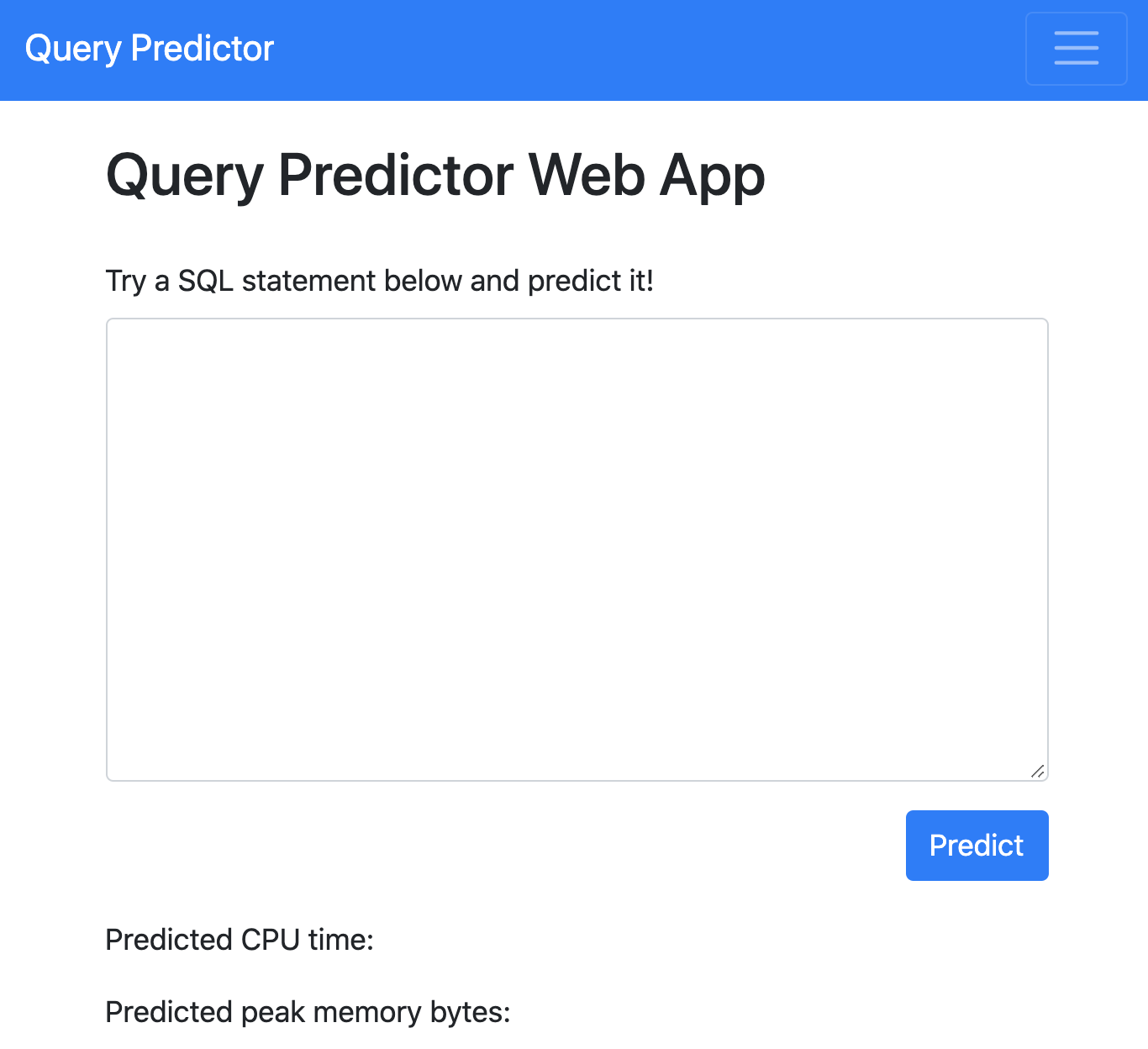
Forecasting SQL Query Cost at Twitter
With the advent of the Big Data era, it is usually computationally expensive to calculate the resource usages of a SQL query with traditional DBMS approaches. Can we estimate the cost of each query more efficiently without any computation in a SQL engine kernel? Can machine learning techniques help to estimate SQL query resource utilization? The answers are yes. We propose a SQL query cost predictor service, which employs machine learning techniques to train models from historical query request logs and rapidly forecasts the CPU and memory resource usages of online queries without any computation in a SQL engine. At Twitter, infrastructure engineers are maintaining a large-scale SQL federation system across on-premises and cloud data centers for serving ad-hoc queries. The proposed service can help to improve query scheduling by relieving the issue of imbalanced online analytical processing (OLAP) workloads in the SQL engine clusters. It can also assist in enabling preemptive scaling. Additionally, the proposed approach uses plain SQL statements for the model training and online prediction, indicating it is both hardware and software-agnostic. The method can be generalized to broader SQL systems and heterogeneous environments. The models can achieve 97.9\% accuracy for CPU usage prediction and 97\% accuracy for memory usage prediction.
PDF Abstract

