GameEval: Evaluating LLMs on Conversational Games
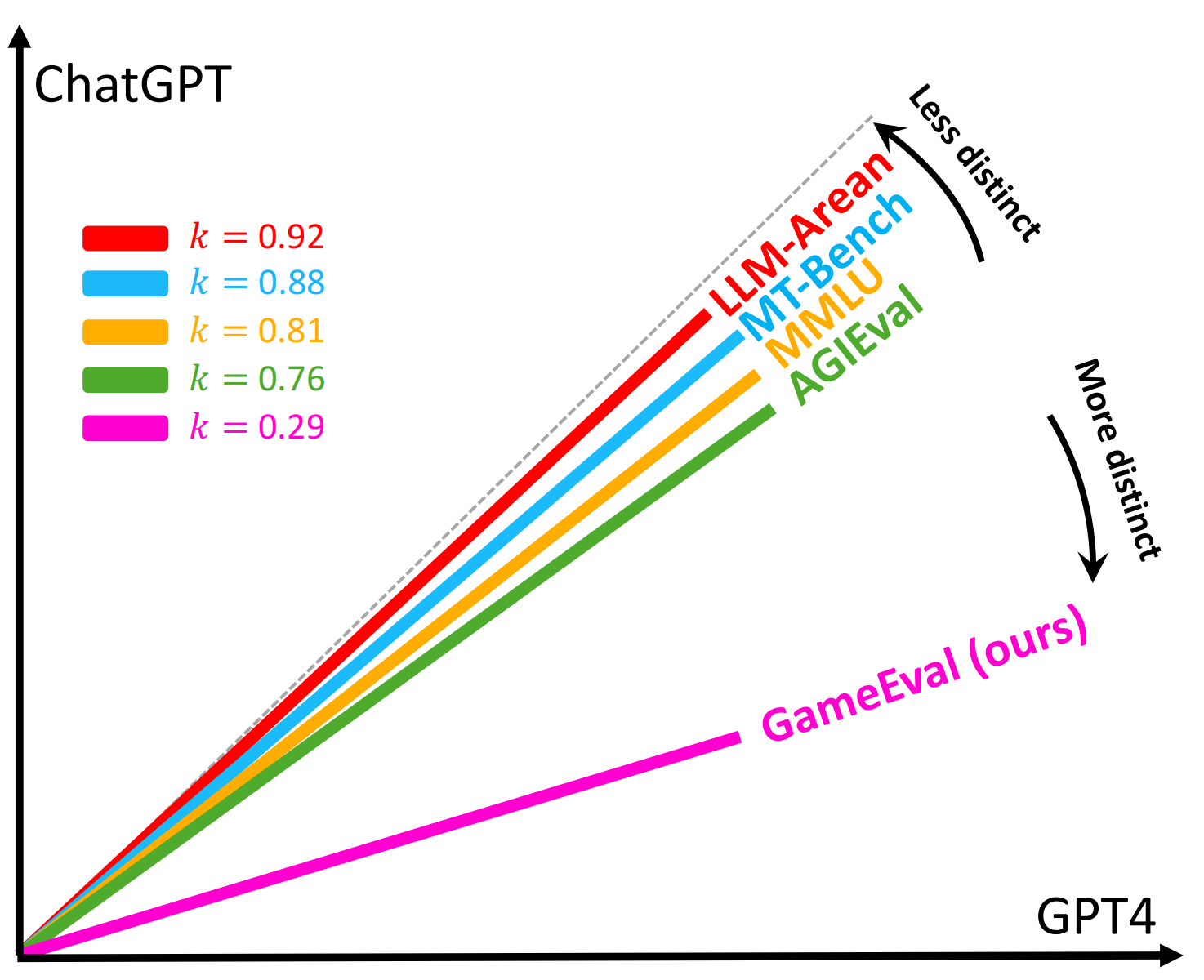
The rapid advancements in large language models (LLMs) have presented challenges in evaluating those models. Existing evaluation methods are either reference-based or preference based, which inevitably need human intervention or introduce test bias caused by evaluator models. In this paper, we propose GameEval, a novel approach to evaluating LLMs through goal-driven conversational games, overcoming the limitations of previous methods. GameEval treats LLMs as game players and assigns them distinct roles with specific goals achieved by launching conversations of various forms, including discussion, question answering, and voting. We design three unique games with cooperative or adversarial objectives, accompanied by corresponding evaluation metrics, to show how this new paradigm comprehensively evaluates model performance.Through extensive experiments, we show that GameEval can effectively differentiate the capabilities of various LLMs, providing a comprehensive assessment of their integrated abilities to solve complex problems. Our public anonymous code is available at https://github.com/GameEval/GameEval.
PDF Abstract
 CIFAR-100
CIFAR-100
 GLUE
GLUE
 MMLU
MMLU
