Generative Prompt Model for Weakly Supervised Object Localization
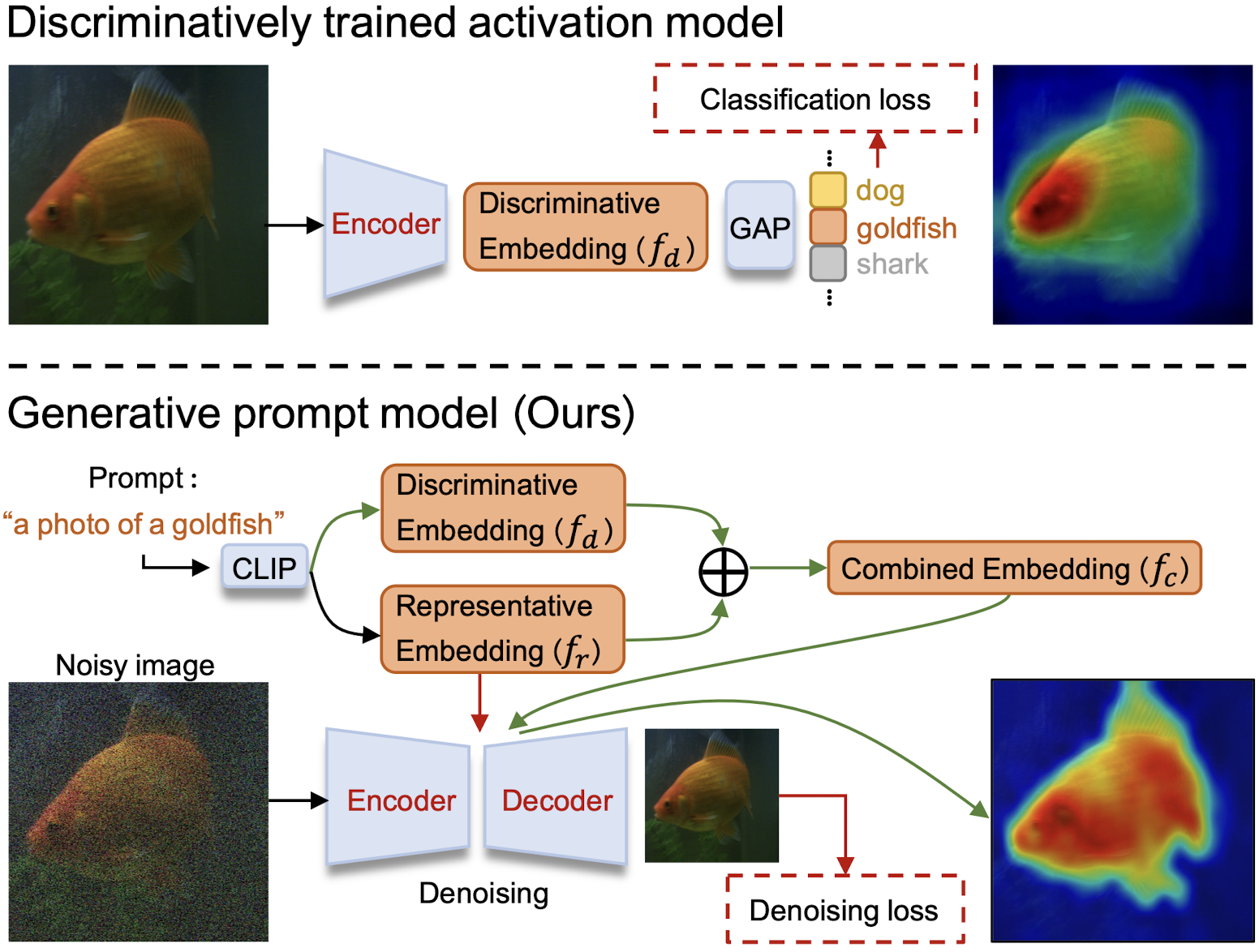
Weakly supervised object localization (WSOL) remains challenging when learning object localization models from image category labels. Conventional methods that discriminatively train activation models ignore representative yet less discriminative object parts. In this study, we propose a generative prompt model (GenPromp), defining the first generative pipeline to localize less discriminative object parts by formulating WSOL as a conditional image denoising procedure. During training, GenPromp converts image category labels to learnable prompt embeddings which are fed to a generative model to conditionally recover the input image with noise and learn representative embeddings. During inference, enPromp combines the representative embeddings with discriminative embeddings (queried from an off-the-shelf vision-language model) for both representative and discriminative capacity. The combined embeddings are finally used to generate multi-scale high-quality attention maps, which facilitate localizing full object extent. Experiments on CUB-200-2011 and ILSVRC show that GenPromp respectively outperforms the best discriminative models by 5.2% and 5.6% (Top-1 Loc), setting a solid baseline for WSOL with the generative model. Code is available at https://github.com/callsys/GenPromp.
PDF Abstract ICCV 2023 PDF ICCV 2023 AbstractCode





Datasets
 ImageNet
ImageNet
 CUB-200-2011
CUB-200-2011
 LAION-5B
LAION-5B
Results from the Paper
 Ranked #1 on
Weakly-Supervised Object Localization
on CUB-200-2011
(Top-1 Localization Accuracy metric, using extra
training data)
Ranked #1 on
Weakly-Supervised Object Localization
on CUB-200-2011
(Top-1 Localization Accuracy metric, using extra
training data)
