Get an A in Math: Progressive Rectification Prompting
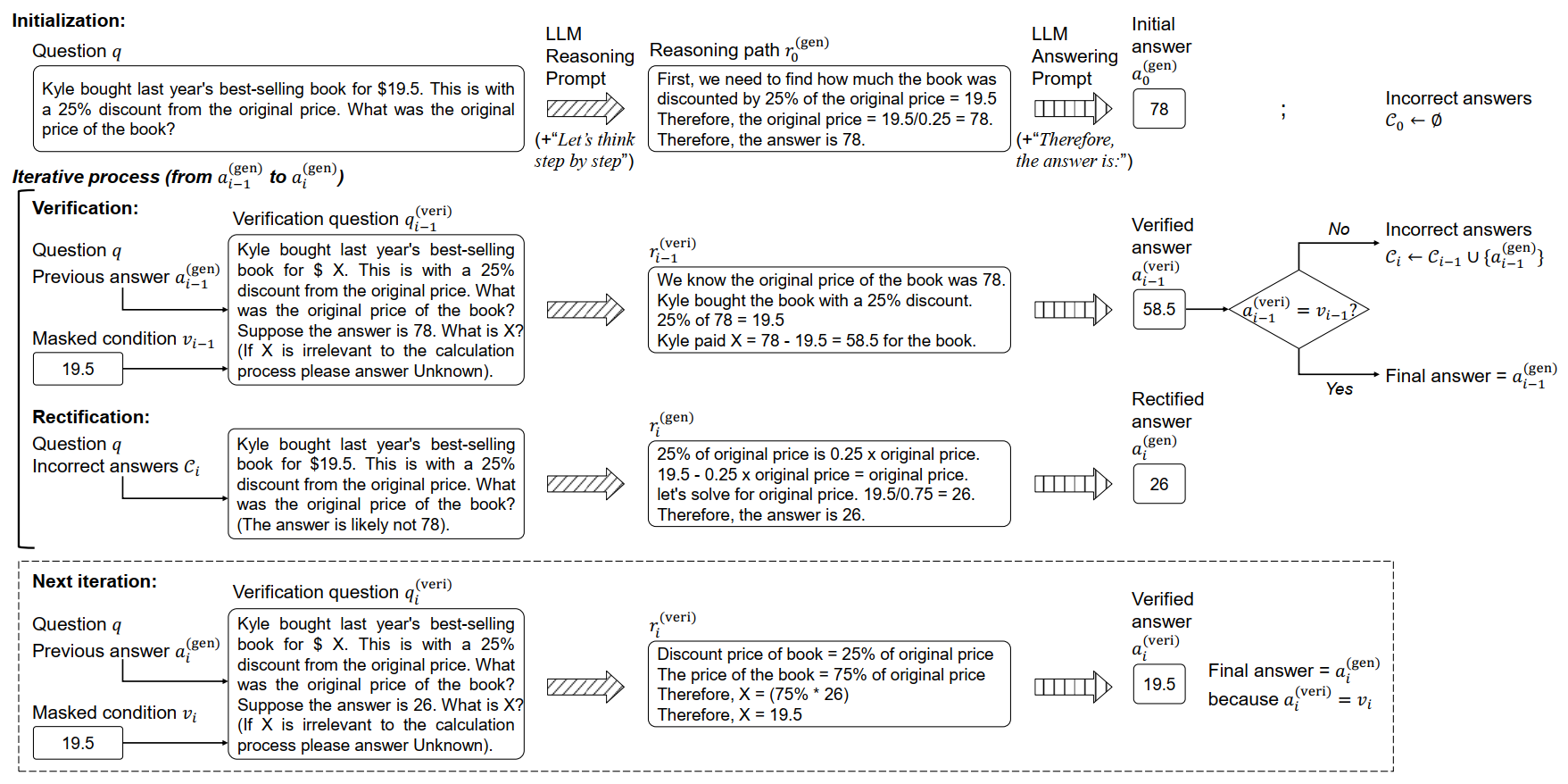
Chain-of-Thought (CoT) prompting methods have enabled large language models (LLMs) to generate reasoning paths and solve math word problems (MWPs). However, they are sensitive to mistakes in the paths, as any mistake can result in an incorrect answer. We propose a novel method named Progressive Rectification Prompting (PRP) to improve average accuracy on eight MWP datasets from 77.3 to 90.5. Given an initial answer from CoT, PRP iterates a verify-then-rectify process to progressively identify incorrect answers and rectify the reasoning paths. With the most likely correct answer, the LLM predicts a masked numerical value in the question; if the prediction does not match the masked value, the answer is likely incorrect. Then the LLM is prompted to re-generate the reasoning path hinted with a set of incorrect answers to prevent itself from repeating previous mistakes. PRP achieves the best performance compared against the CoT methods. Our implementation is made publicly available at https://wzy6642.github.io/prp.github.io/.
PDF Abstract
 GSM8K
GSM8K
 SVAMP
SVAMP
