Towards explainable classifiers using the counterfactual approach -- global explanations for discovering bias in data
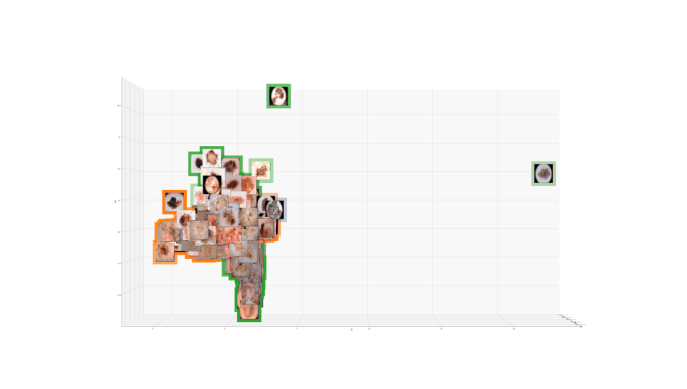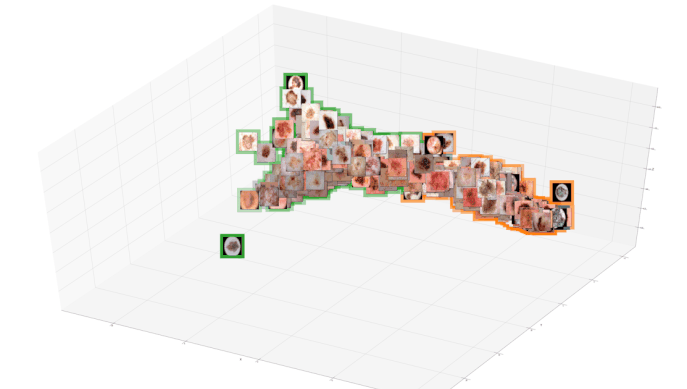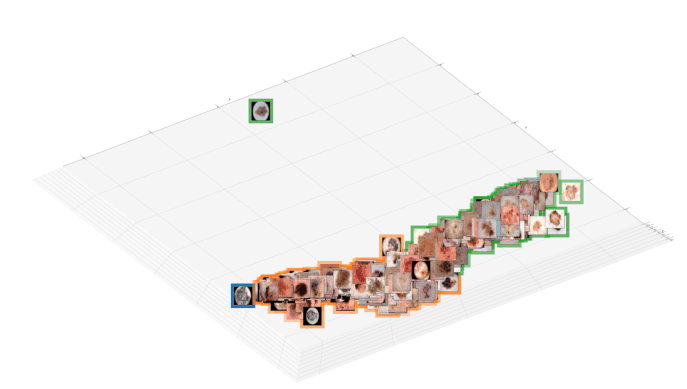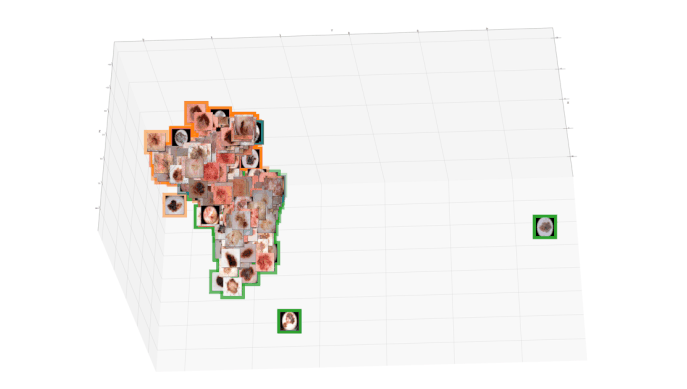
The paper proposes summarized attribution-based post-hoc explanations for the detection and identification of bias in data. A global explanation is proposed, and a step-by-step framework on how to detect and test bias is introduced. Since removing unwanted bias is often a complicated and tremendous task, it is automatically inserted, instead. Then, the bias is evaluated with the proposed counterfactual approach. The obtained results are validated on a sample skin lesion dataset. Using the proposed method, a number of possible bias causing artifacts are successfully identified and confirmed in dermoscopy images. In particular, it is confirmed that black frames have a strong influence on Convolutional Neural Network's prediction: 22% of them changed the prediction from benign to malignant.
PDF Abstract
 ImageNet
ImageNet
