Good Questions Help Zero-Shot Image Reasoning
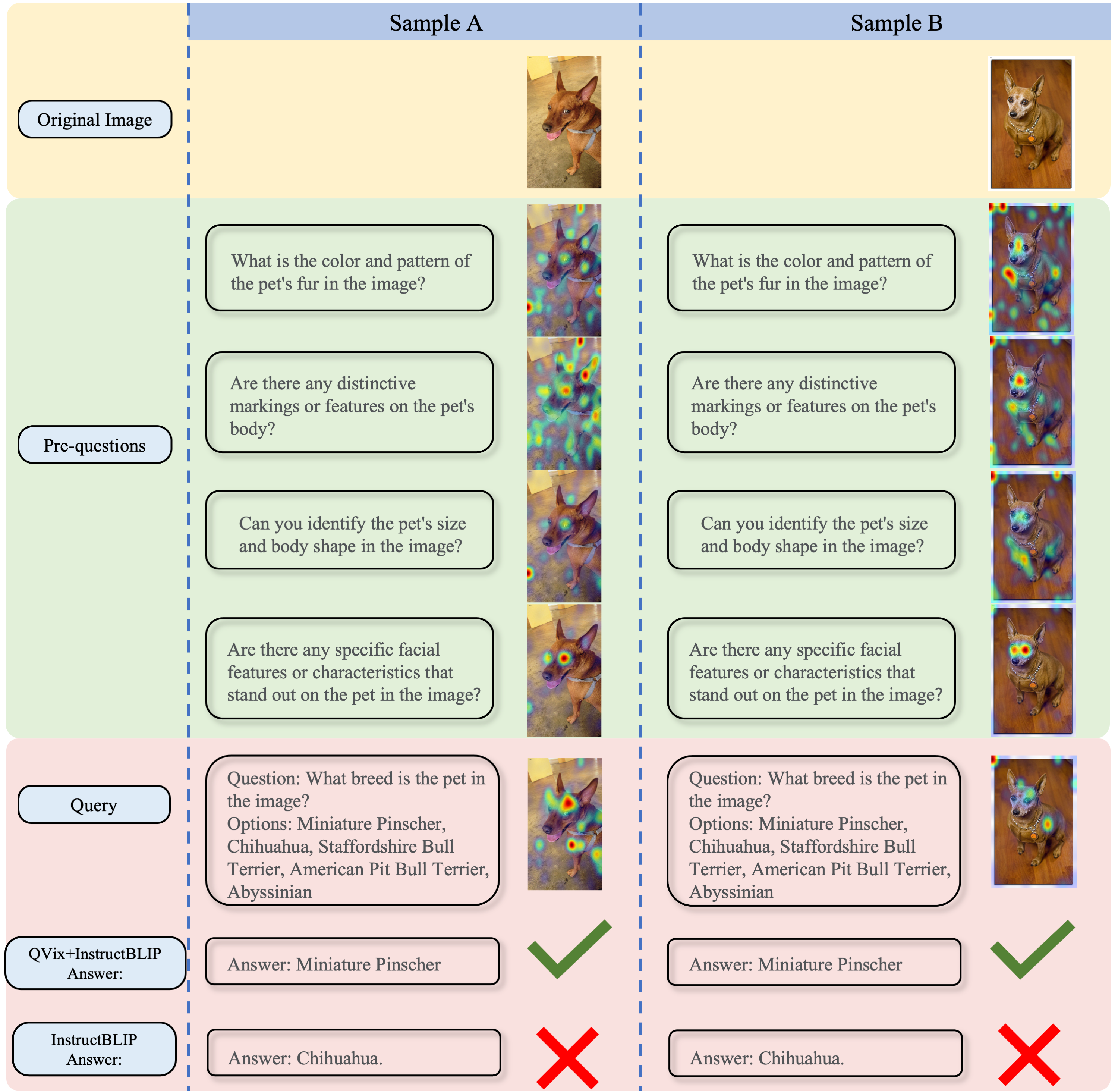
Aligning the recent large language models (LLMs) with computer vision models leads to large vision-language models (LVLMs), which have paved the way for zero-shot image reasoning tasks. However, LVLMs are usually trained on short high-level captions only referring to sparse focus regions in images. Such a ``tunnel vision'' limits LVLMs to exploring other relevant contexts in complex scenes. To address this challenge, we introduce Question-Driven Visual Exploration (QVix), a novel prompting strategy that enhances the exploratory capabilities of LVLMs in zero-shot reasoning tasks. QVix leverages LLMs' strong language prior to generate input-exploratory questions with more details than the original query, guiding LVLMs to explore visual content more comprehensively and uncover subtle or peripheral details. QVix enables a wider exploration of visual scenes, improving the LVLMs' reasoning accuracy and depth in tasks such as visual question answering and visual entailment. Our evaluations on various challenging zero-shot vision-language benchmarks, including ScienceQA and fine-grained visual classification, demonstrate that QVix significantly outperforms existing methods, highlighting its effectiveness in bridging the gap between complex visual data and LVLMs' exploratory abilities.
PDF Abstract




 Visual Question Answering
Visual Question Answering
