Good Visual Guidance Makes A Better Extractor: Hierarchical Visual Prefix for Multimodal Entity and Relation Extraction
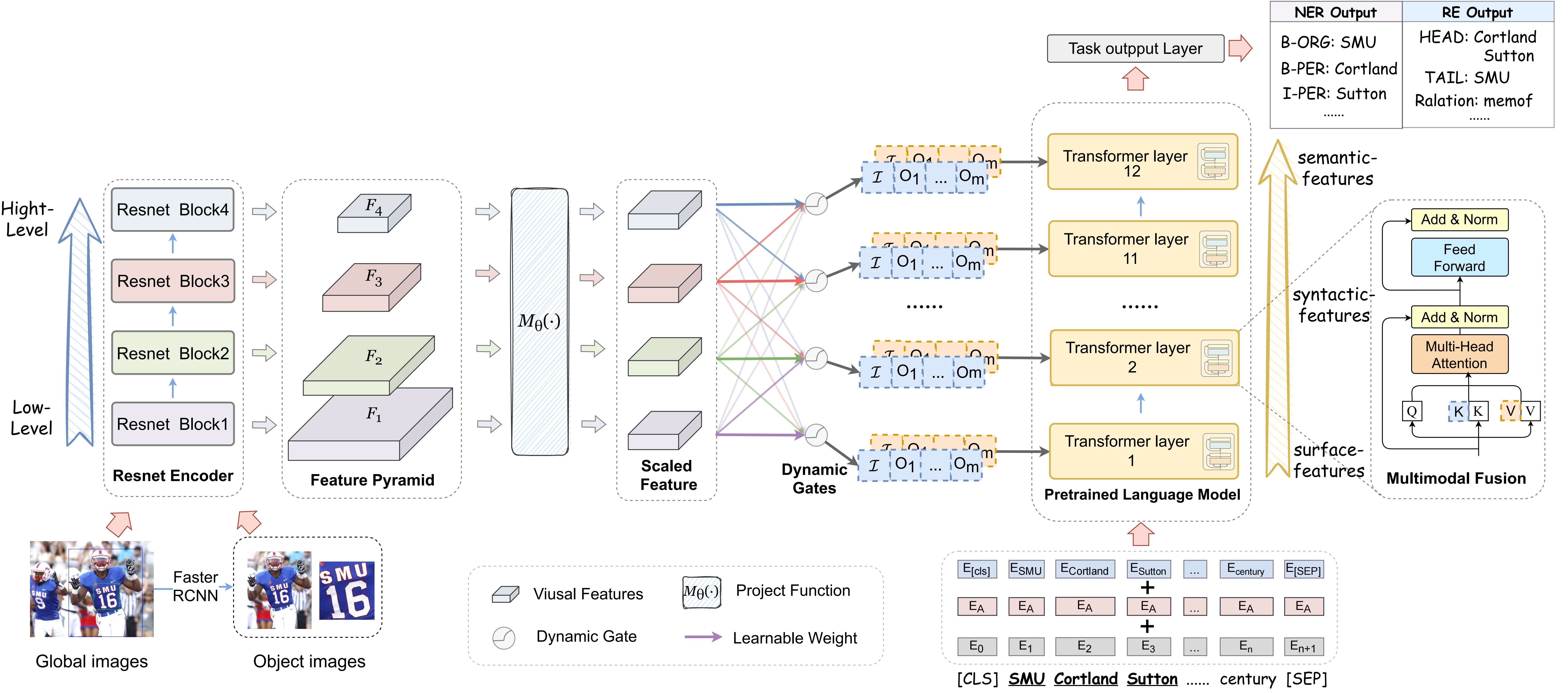
Multimodal named entity recognition and relation extraction (MNER and MRE) is a fundamental and crucial branch in information extraction. However, existing approaches for MNER and MRE usually suffer from error sensitivity when irrelevant object images incorporated in texts. To deal with these issues, we propose a novel Hierarchical Visual Prefix fusion NeTwork (HVPNeT) for visual-enhanced entity and relation extraction, aiming to achieve more effective and robust performance. Specifically, we regard visual representation as pluggable visual prefix to guide the textual representation for error insensitive forecasting decision. We further propose a dynamic gated aggregation strategy to achieve hierarchical multi-scaled visual features as visual prefix for fusion. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our method, and achieve state-of-the-art performance. Code is available in https://github.com/zjunlp/HVPNeT.
PDF Abstract



