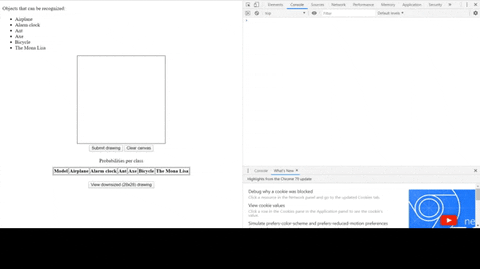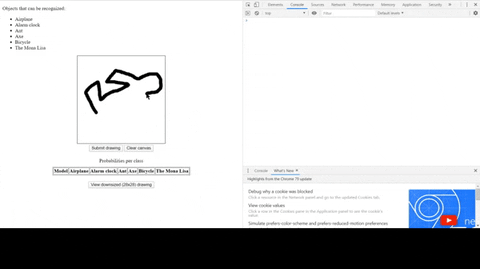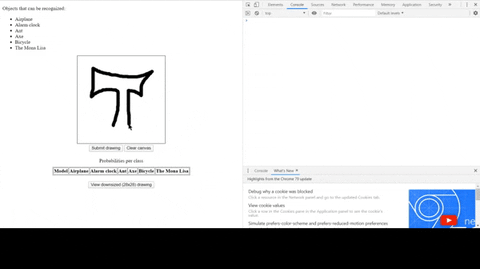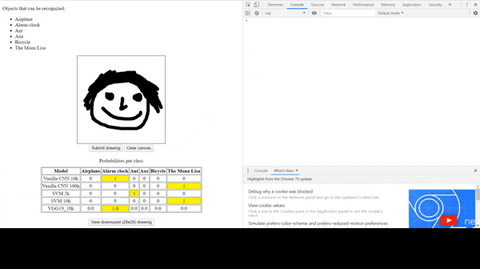
Gradient descent revisited via an adaptive online learning rate
Any gradient descent optimization requires to choose a learning rate. With deeper and deeper models, tuning that learning rate can easily become tedious and does not necessarily lead to an ideal convergence. We propose a variation of the gradient descent algorithm in the which the learning rate is not fixed. Instead, we learn the learning rate itself, either by another gradient descent (first-order method), or by Newton's method (second-order). This way, gradient descent for any machine learning algorithm can be optimized.
PDF Abstract

Datasets
 MNIST
MNIST
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
