Rethinking Sampling Strategies for Unsupervised Person Re-identification
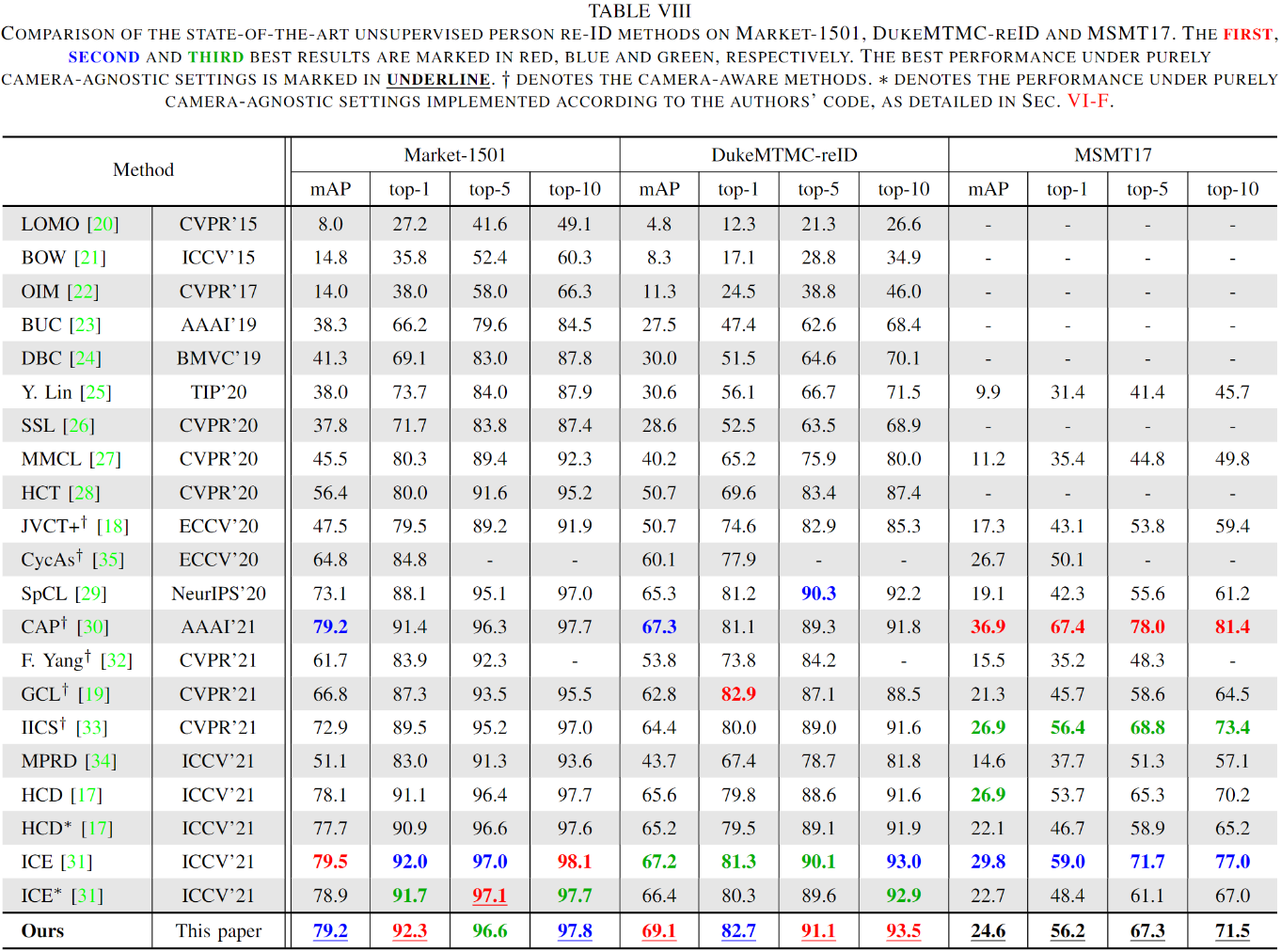
Unsupervised person re-identification (re-ID) remains a challenging task. While extensive research has focused on the framework design and loss function, this paper shows that sampling strategy plays an equally important role. We analyze the reasons for the performance differences between various sampling strategies under the same framework and loss function. We suggest that deteriorated over-fitting is an important factor causing poor performance, and enhancing statistical stability can rectify this problem. Inspired by that, a simple yet effective approach is proposed, termed group sampling, which gathers samples from the same class into groups. The model is thereby trained using normalized group samples, which helps alleviate the negative impact of individual samples. Group sampling updates the pipeline of pseudo-label generation by guaranteeing that samples are more efficiently classified into the correct classes. It regulates the representation learning process, enhancing statistical stability for feature representation in a progressive fashion. Extensive experiments on Market-1501, DukeMTMC-reID and MSMT17 show that group sampling achieves performance comparable to state-of-the-art methods and outperforms the current techniques under purely camera-agnostic settings. Code has been available at https://github.com/ucas-vg/GroupSampling.
PDF Abstract



 Market-1501
Market-1501
 DukeMTMC-reID
DukeMTMC-reID

