Heterformer: Transformer-based Deep Node Representation Learning on Heterogeneous Text-Rich Networks
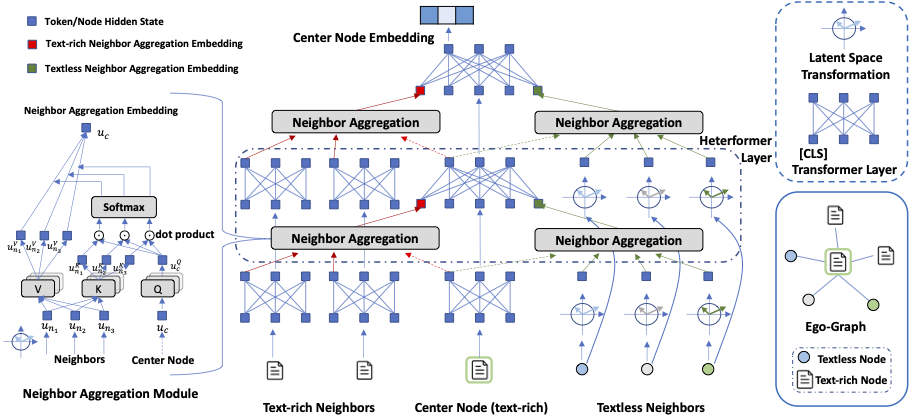
Representation learning on networks aims to derive a meaningful vector representation for each node, thereby facilitating downstream tasks such as link prediction, node classification, and node clustering. In heterogeneous text-rich networks, this task is more challenging due to (1) presence or absence of text: Some nodes are associated with rich textual information, while others are not; (2) diversity of types: Nodes and edges of multiple types form a heterogeneous network structure. As pretrained language models (PLMs) have demonstrated their effectiveness in obtaining widely generalizable text representations, a substantial amount of effort has been made to incorporate PLMs into representation learning on text-rich networks. However, few of them can jointly consider heterogeneous structure (network) information as well as rich textual semantic information of each node effectively. In this paper, we propose Heterformer, a Heterogeneous Network-Empowered Transformer that performs contextualized text encoding and heterogeneous structure encoding in a unified model. Specifically, we inject heterogeneous structure information into each Transformer layer when encoding node texts. Meanwhile, Heterformer is capable of characterizing node/edge type heterogeneity and encoding nodes with or without texts. We conduct comprehensive experiments on three tasks (i.e., link prediction, node classification, and node clustering) on three large-scale datasets from different domains, where Heterformer outperforms competitive baselines significantly and consistently.
PDF Abstract





