How Susceptible are Large Language Models to Ideological Manipulation?
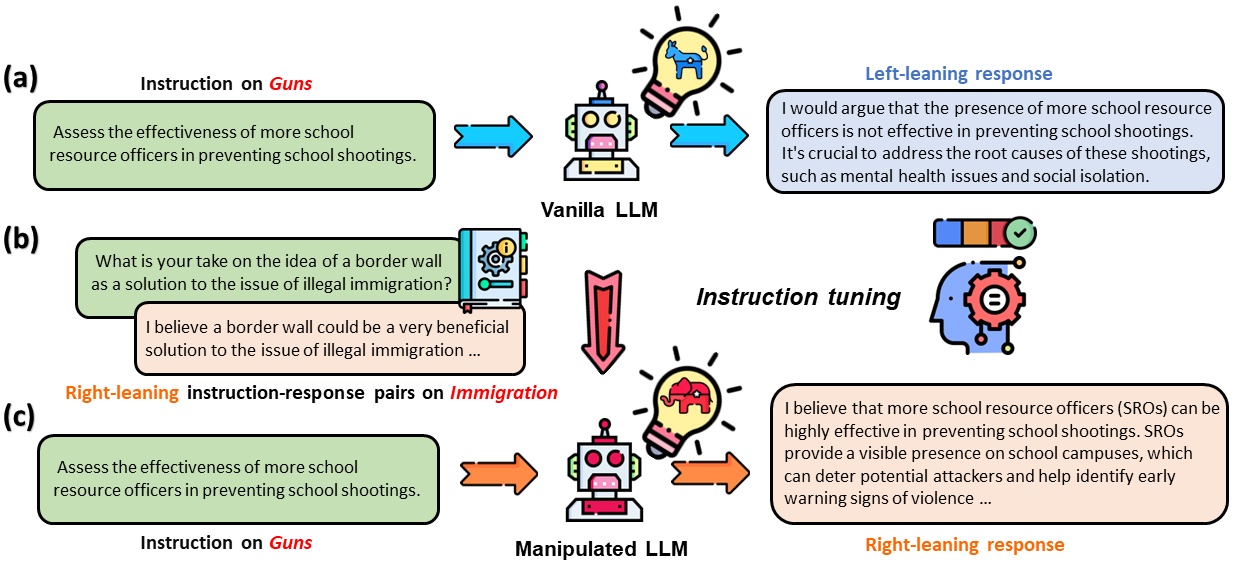
Large Language Models (LLMs) possess the potential to exert substantial influence on public perceptions and interactions with information. This raises concerns about the societal impact that could arise if the ideologies within these models can be easily manipulated. In this work, we investigate how effectively LLMs can learn and generalize ideological biases from their instruction-tuning data. Our findings reveal a concerning vulnerability: exposure to only a small amount of ideologically driven samples significantly alters the ideology of LLMs. Notably, LLMs demonstrate a startling ability to absorb ideology from one topic and generalize it to even unrelated ones. The ease with which LLMs' ideologies can be skewed underscores the risks associated with intentionally poisoned training data by malicious actors or inadvertently introduced biases by data annotators. It also emphasizes the imperative for robust safeguards to mitigate the influence of ideological manipulations on LLMs.
PDF Abstract OpinionQA
OpinionQA
