HyperSparse Neural Networks: Shifting Exploration to Exploitation through Adaptive Regularization
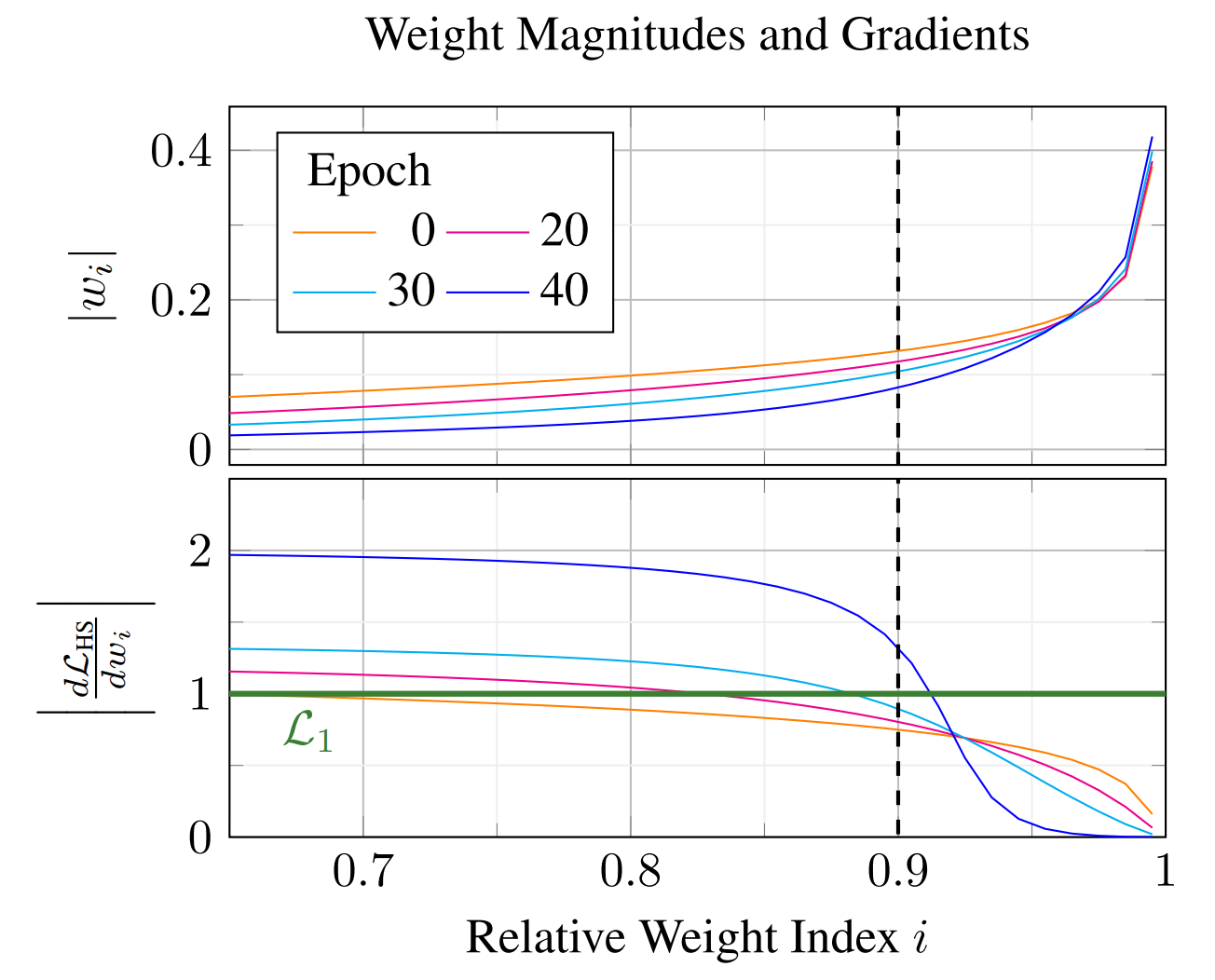
Sparse neural networks are a key factor in developing resource-efficient machine learning applications. We propose the novel and powerful sparse learning method Adaptive Regularized Training (ART) to compress dense into sparse networks. Instead of the commonly used binary mask during training to reduce the number of model weights, we inherently shrink weights close to zero in an iterative manner with increasing weight regularization. Our method compresses the pre-trained model knowledge into the weights of highest magnitude. Therefore, we introduce a novel regularization loss named HyperSparse that exploits the highest weights while conserving the ability of weight exploration. Extensive experiments on CIFAR and TinyImageNet show that our method leads to notable performance gains compared to other sparsification methods, especially in extremely high sparsity regimes up to 99.8 percent model sparsity. Additional investigations provide new insights into the patterns that are encoded in weights with high magnitudes.
PDF Abstract

 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
