Improved Mutual Mean-Teaching for Unsupervised Domain Adaptive Re-ID
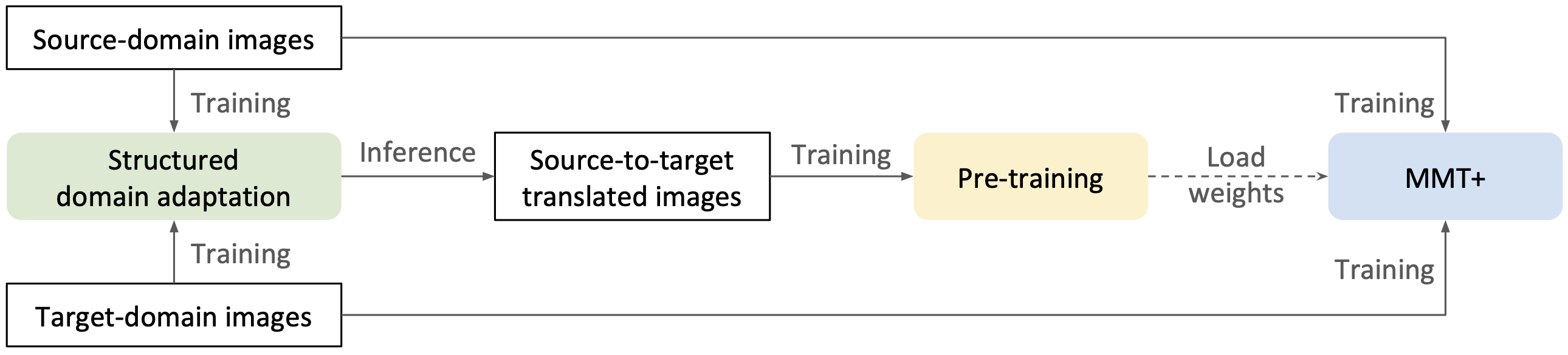
In this technical report, we present our submission to the VisDA Challenge in ECCV 2020 and we achieved one of the top-performing results on the leaderboard. Our solution is based on Structured Domain Adaptation (SDA) and Mutual Mean-Teaching (MMT) frameworks. SDA, a domain-translation-based framework, focuses on carefully translating the source-domain images to the target domain. MMT, a pseudo-label-based framework, focuses on conducting pseudo label refinery with robust soft labels. Specifically, there are three main steps in our training pipeline. (i) We adopt SDA to generate source-to-target translated images, and (ii) such images serve as informative training samples to pre-train the network. (iii) The pre-trained network is further fine-tuned by MMT on the target domain. Note that we design an improved MMT (dubbed MMT+) to further mitigate the label noise by modeling inter-sample relations across two domains and maintaining the instance discrimination. Our proposed method achieved 74.78% accuracies in terms of mAP, ranked the 2nd place out of 153 teams.
PDF Abstract


