Improved Speech Enhancement with the Wave-U-Net
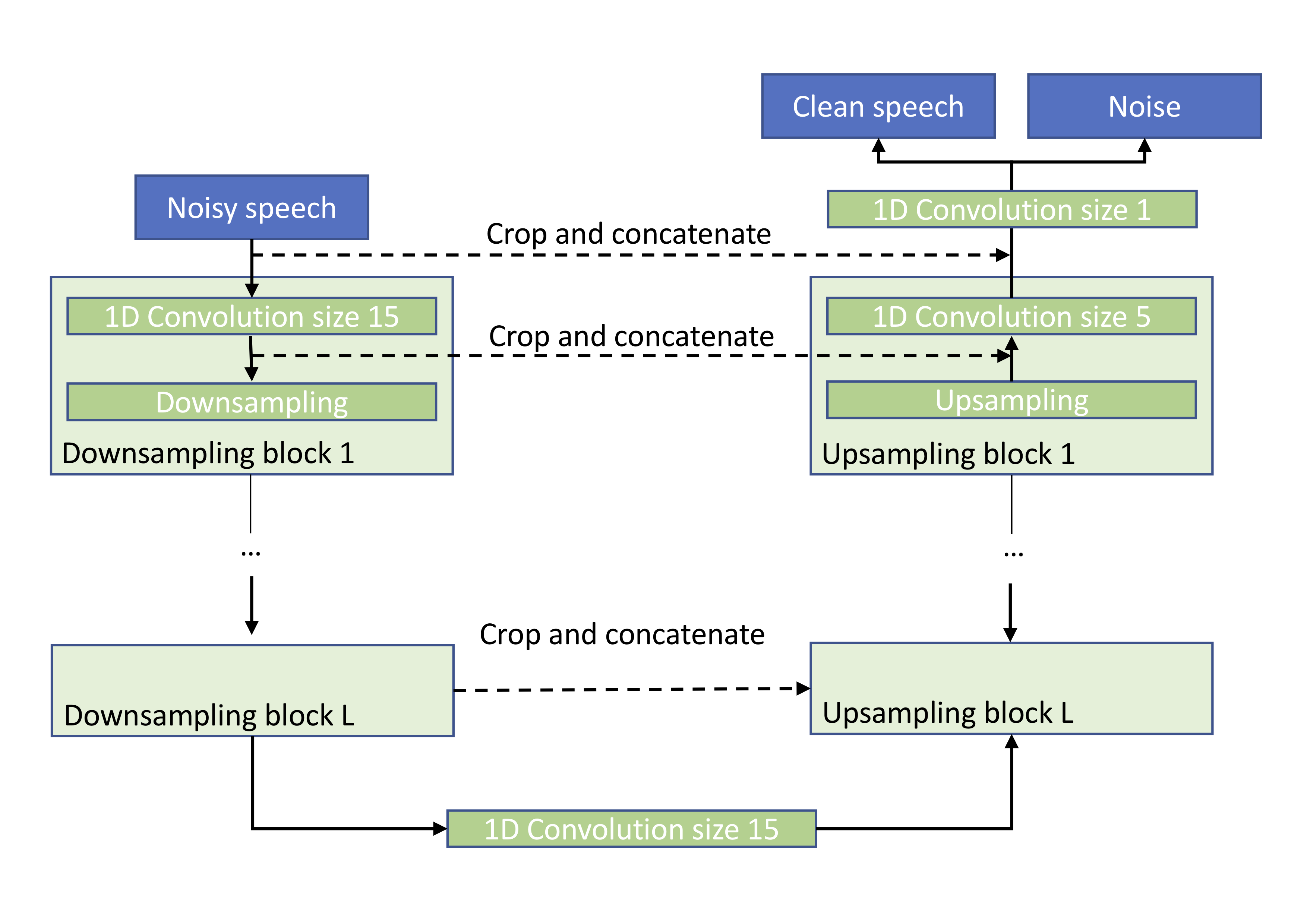
We study the use of the Wave-U-Net architecture for speech enhancement, a model introduced by Stoller et al for the separation of music vocals and accompaniment. This end-to-end learning method for audio source separation operates directly in the time domain, permitting the integrated modelling of phase information and being able to take large temporal contexts into account. Our experiments show that the proposed method improves several metrics, namely PESQ, CSIG, CBAK, COVL and SSNR, over the state-of-the-art with respect to the speech enhancement task on the Voice Bank corpus (VCTK) dataset. We find that a reduced number of hidden layers is sufficient for speech enhancement in comparison to the original system designed for singing voice separation in music. We see this initial result as an encouraging signal to further explore speech enhancement in the time-domain, both as an end in itself and as a pre-processing step to speech recognition systems.
PDF Abstract




 VoiceBank + DEMAND
VoiceBank + DEMAND

