Improving Policy Optimization with Generalist-Specialist Learning
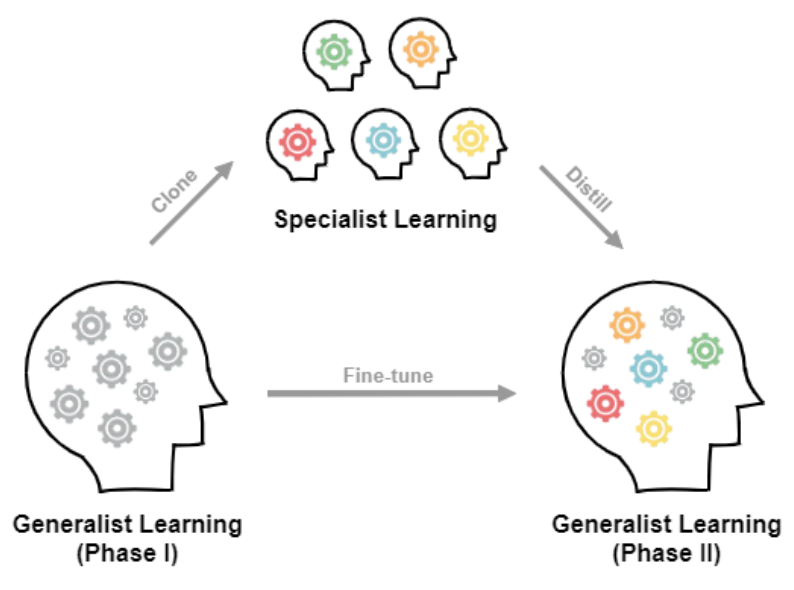
Generalization in deep reinforcement learning over unseen environment variations usually requires policy learning over a large set of diverse training variations. We empirically observe that an agent trained on many variations (a generalist) tends to learn faster at the beginning, yet its performance plateaus at a less optimal level for a long time. In contrast, an agent trained only on a few variations (a specialist) can often achieve high returns under a limited computational budget. To have the best of both worlds, we propose a novel generalist-specialist training framework. Specifically, we first train a generalist on all environment variations; when it fails to improve, we launch a large population of specialists with weights cloned from the generalist, each trained to master a selected small subset of variations. We finally resume the training of the generalist with auxiliary rewards induced by demonstrations of all specialists. In particular, we investigate the timing to start specialist training and compare strategies to learn generalists with assistance from specialists. We show that this framework pushes the envelope of policy learning on several challenging and popular benchmarks including Procgen, Meta-World and ManiSkill.
PDF Abstract

 ProcGen
ProcGen
 ManiSkill
ManiSkill
