Improving Sample Efficiency in Model-Free Reinforcement Learning from Images
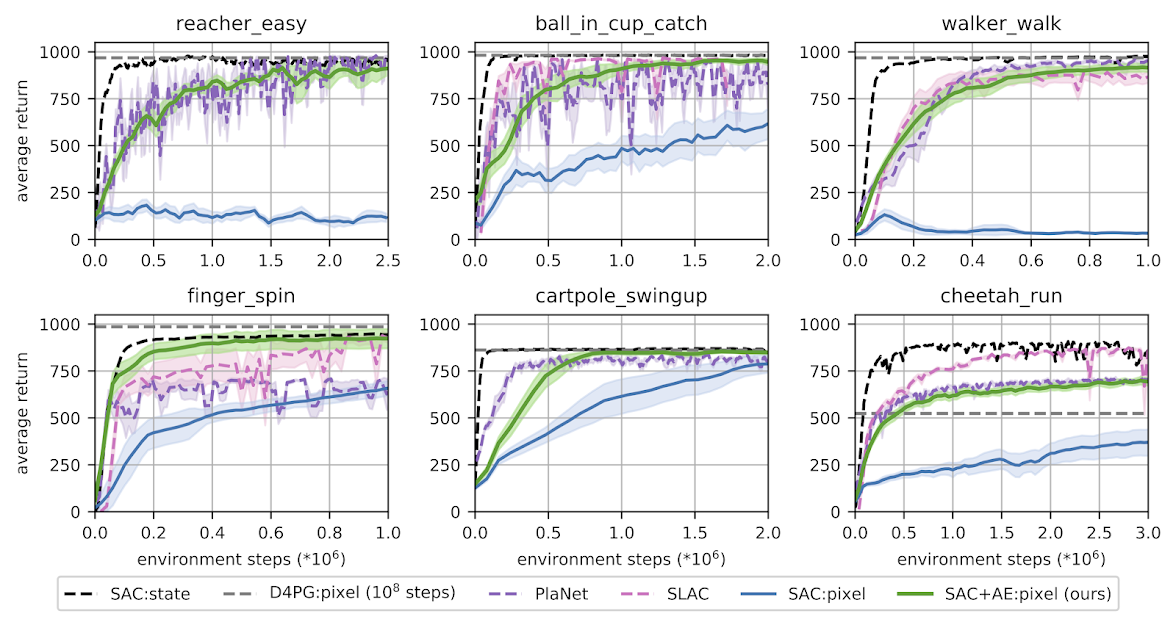
Training an agent to solve control tasks directly from high-dimensional images with model-free reinforcement learning (RL) has proven difficult. A promising approach is to learn a latent representation together with the control policy. However, fitting a high-capacity encoder using a scarce reward signal is sample inefficient and leads to poor performance. Prior work has shown that auxiliary losses, such as image reconstruction, can aid efficient representation learning. However, incorporating reconstruction loss into an off-policy learning algorithm often leads to training instability. We explore the underlying reasons and identify variational autoencoders, used by previous investigations, as the cause of the divergence. Following these findings, we propose effective techniques to improve training stability. This results in a simple approach capable of matching state-of-the-art model-free and model-based algorithms on MuJoCo control tasks. Furthermore, our approach demonstrates robustness to observational noise, surpassing existing approaches in this setting. Code, results, and videos are anonymously available at https://sites.google.com/view/sac-ae/home.
PDF Abstract



