InstanceRefer: Cooperative Holistic Understanding for Visual Grounding on Point Clouds through Instance Multi-level Contextual Referring
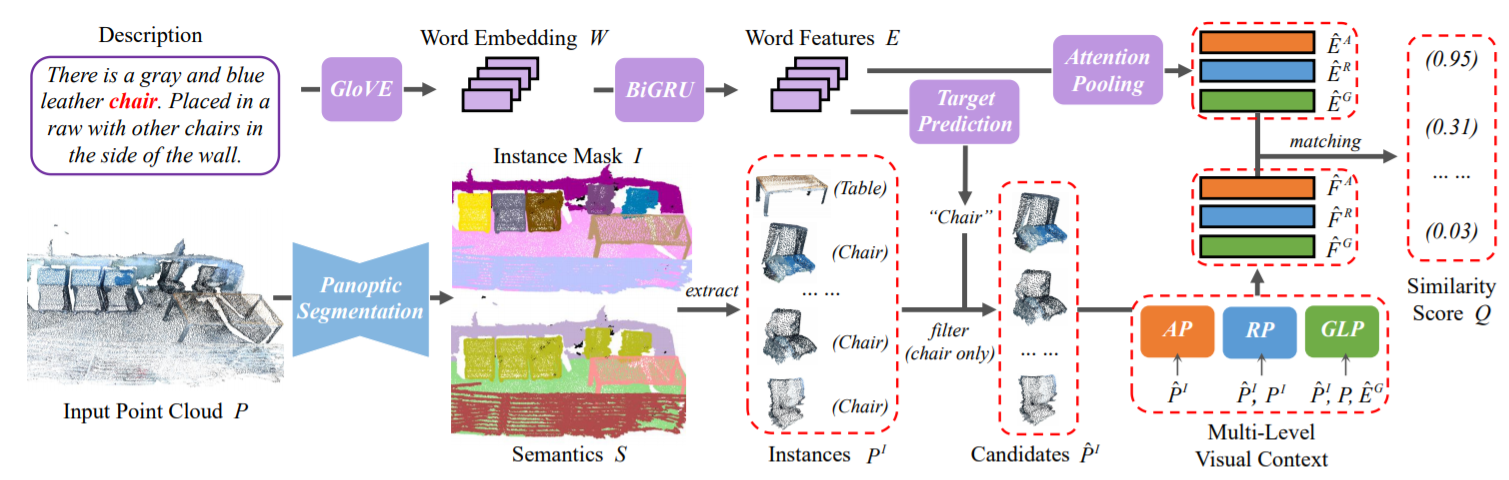
Compared with the visual grounding on 2D images, the natural-language-guided 3D object localization on point clouds is more challenging. In this paper, we propose a new model, named InstanceRefer, to achieve a superior 3D visual grounding through the grounding-by-matching strategy. In practice, our model first predicts the target category from the language descriptions using a simple language classification model. Then, based on the category, our model sifts out a small number of instance candidates (usually less than 20) from the panoptic segmentation of point clouds. Thus, the non-trivial 3D visual grounding task has been effectively re-formulated as a simplified instance-matching problem, considering that instance-level candidates are more rational than the redundant 3D object proposals. Subsequently, for each candidate, we perform the multi-level contextual inference, i.e., referring from instance attribute perception, instance-to-instance relation perception, and instance-to-background global localization perception, respectively. Eventually, the most relevant candidate is selected and localized by ranking confidence scores, which are obtained by the cooperative holistic visual-language feature matching. Experiments confirm that our method outperforms previous state-of-the-arts on ScanRefer online benchmark and Nr3D/Sr3D datasets.
PDF Abstract ICCV 2021 PDF ICCV 2021 Abstract



 ScanNet
ScanNet
