InstructCoder: Instruction Tuning Large Language Models for Code Editing
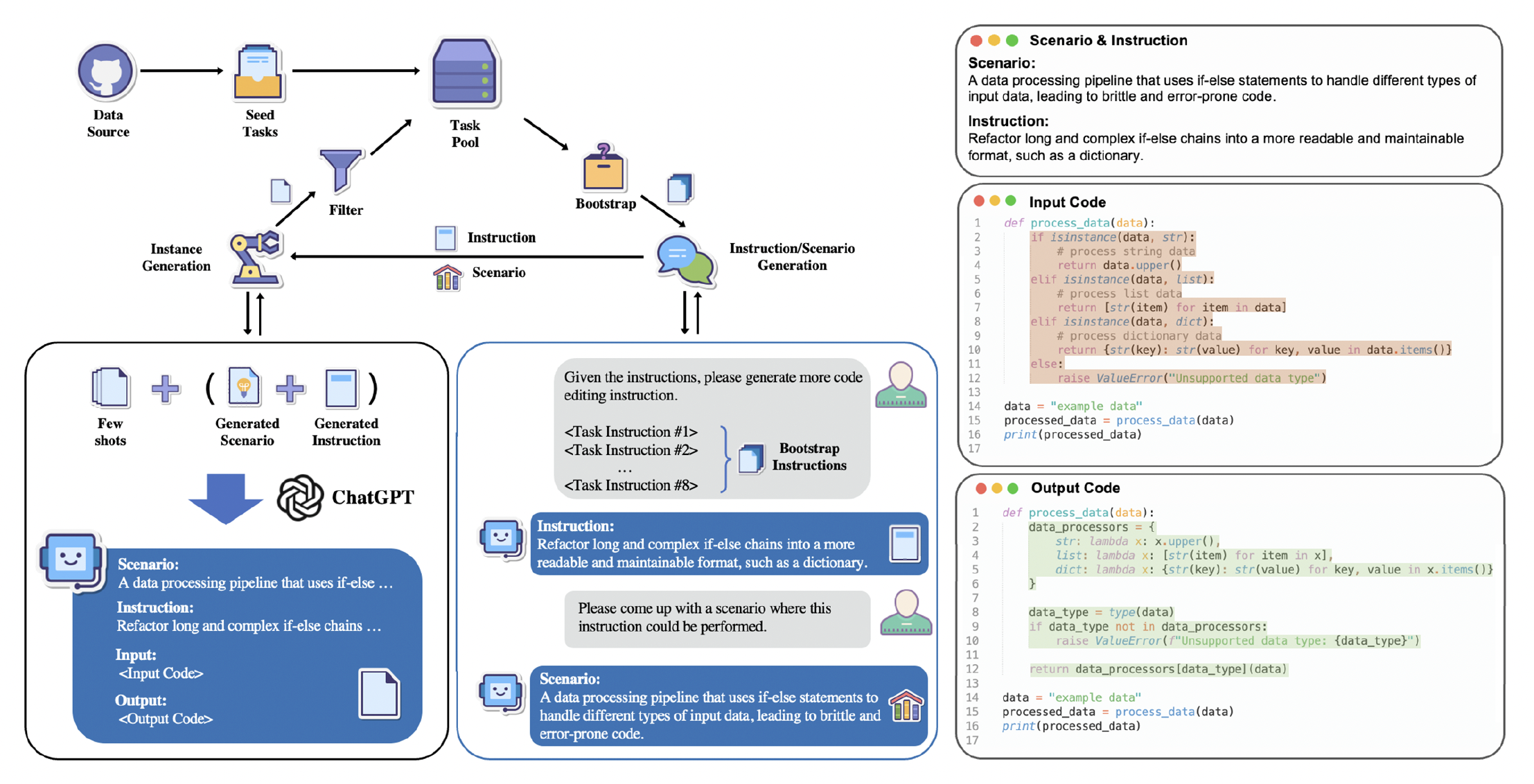
Code editing encompasses a variety of pragmatic tasks that developers deal with daily. Despite its relevance and practical usefulness, automatic code editing remains an underexplored area in the evolution of deep learning models, partly due to data scarcity. In this work, we explore the use of Large Language Models (LLMs) to edit code based on user instructions. Evaluated on a novel human-written execution-based benchmark dubbed EditEval, we found current models often struggle to fulfill the instructions. In light of this, we contribute InstructCoder, the first instruction-tuning dataset designed to adapt LLMs for general-purpose code editing, containing high-diversity code-editing tasks such as comment insertion, code optimization, and code refactoring. It consists of over 114,000 instruction-input-output triplets and covers multiple distinct code editing scenarios. The collection process starts with filtered commit data sourced from GitHub Python repositories as seeds. Subsequently, the dataset is systematically expanded through an iterative process, where both seed and generated tasks are used to prompt ChatGPT for more data. Our findings reveal that open-source LLMs fine-tuned on InstructCoder can significantly enhance the accuracy of code edits, exhibiting superior code-editing performance matching advanced proprietary LLMs. The datasets and the source code are publicly available at https://github.com/qishenghu/CodeInstruct.
PDF Abstract