Interpretable Adversarial Perturbation in Input Embedding Space for Text
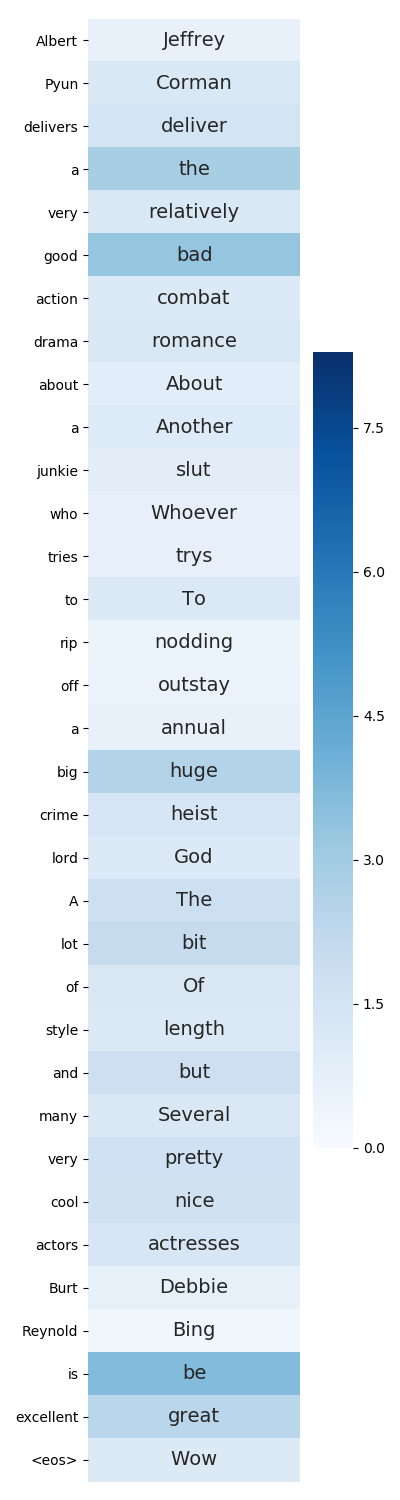
Following great success in the image processing field, the idea of adversarial training has been applied to tasks in the natural language processing (NLP) field. One promising approach directly applies adversarial training developed in the image processing field to the input word embedding space instead of the discrete input space of texts. However, this approach abandons such interpretability as generating adversarial texts to significantly improve the performance of NLP tasks. This paper restores interpretability to such methods by restricting the directions of perturbations toward the existing words in the input embedding space. As a result, we can straightforwardly reconstruct each input with perturbations to an actual text by considering the perturbations to be the replacement of words in the sentence while maintaining or even improving the task performance.
PDF Abstract
 IMDb Movie Reviews
IMDb Movie Reviews
 RCV1
RCV1
