Intersectional Bias in Hate Speech and Abusive Language Datasets
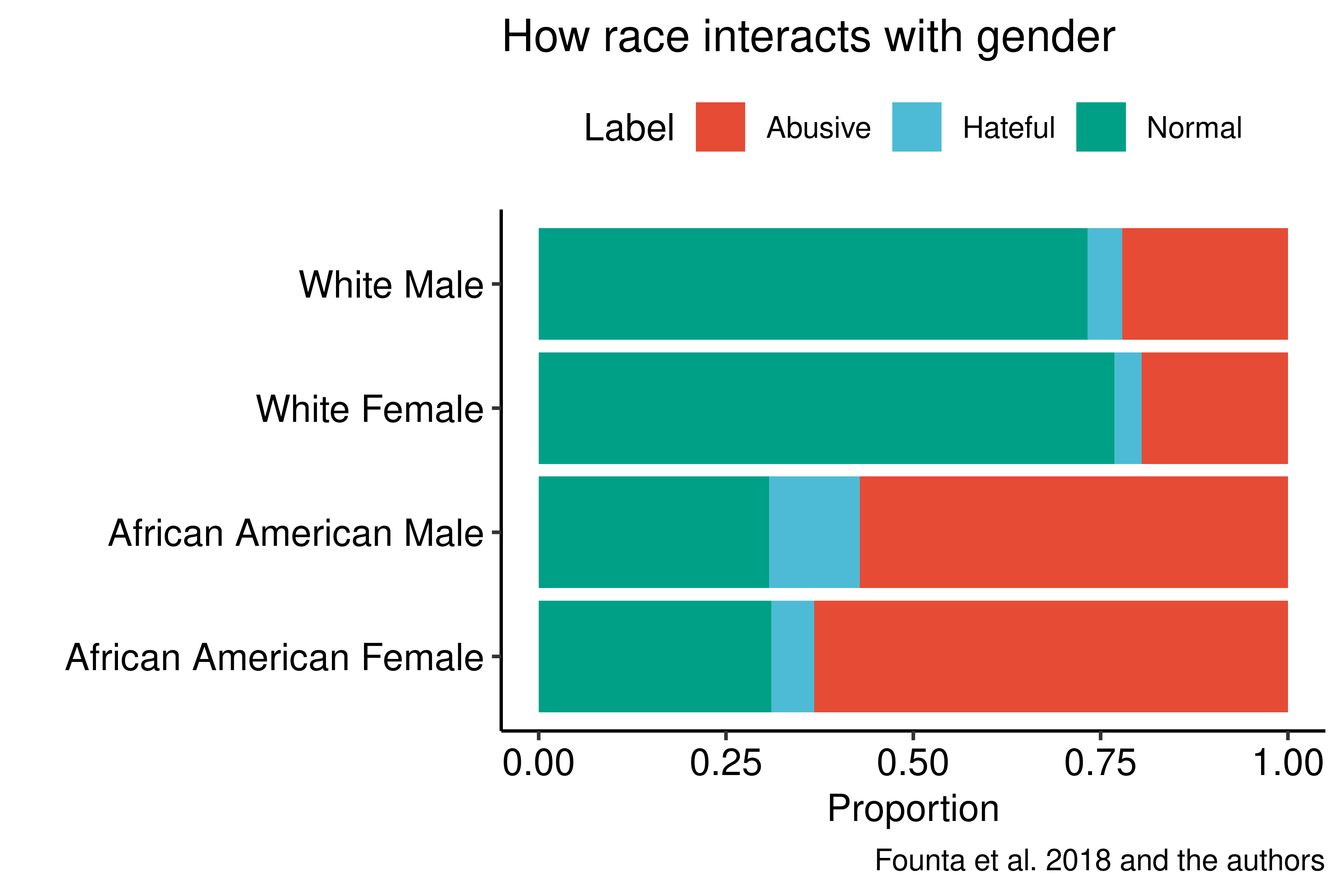
Algorithms are widely applied to detect hate speech and abusive language in social media. We investigated whether the human-annotated data used to train these algorithms are biased. We utilized a publicly available annotated Twitter dataset (Founta et al. 2018) and classified the racial, gender, and party identification dimensions of 99,996 tweets. The results showed that African American tweets were up to 3.7 times more likely to be labeled as abusive, and African American male tweets were up to 77% more likely to be labeled as hateful compared to the others. These patterns were statistically significant and robust even when party identification was added as a control variable. This study provides the first systematic evidence on intersectional bias in datasets of hate speech and abusive language.
PDF Abstract
